
Hello, I’m Takamitsu Matsubara, an assistant professor in the Intelligent System Control Laboratory. We study on system control, machine learning, reinforcement learning, intelligent robotics, signal processing, and sensing intensively. This article introduces some of our research topics by two PhD students.
If you are further interested in details, please visit our lab’s website: http://genesis.naist.jp/?lang=en
Lorlynn Asuncion Mateo (D1):
Originally from the Philippines, I moved to Japan to join the Intelligent System Control laboratory of NAIST as a research student about 3 years ago. From there, I entered and finished the Master course, then proceeded to enter the doctoral course immediately after graduation. Currently, I am a first year doctoral course student in the said laboratory, undertaking theoretical research on two-degree-of-freedom (2DOF) control.
Initially, my chosen research theme gained much attention in control engineering because of its interesting conception in the biological field. Several years back, Kawato et al. established that biological motor control is achieved by the brain and central nervous system by using a 2DOF structure with a learning law. In this structure, a feedforward (FF) mechanism makes use of feedback (FB) error to achieve accurate motion. This scheme is popularly known as feedback error learning (FEL). To illustrate, a simple figure below shows how the human body functions using this 2DOF structure. In the figure, the controlled object is the pair of limbs used to achieve the motor task, e.g. grabbing an item. Feedback control can be achieved with the help of human vision, while the inverse model and learning law are considered in the human brain. What’s interesting is, deviating from the biological perspective, this idea for adaptive control is very promising and can be applied to any other type of control problem, as done in a lot of existing literature on the subject.

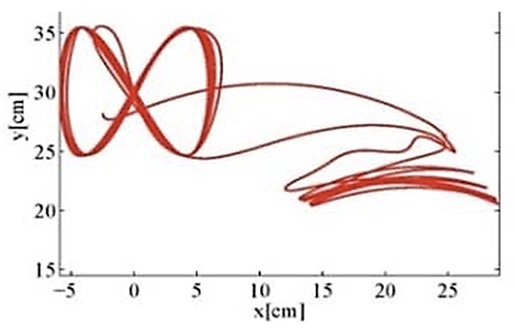
In my PhD study, we design 2DOF control schemes for single-input, single-output (SISO) and multi-input, multi-output (MIMO) plants (model of controlled object). It is known in control theory that the 2DOF configuration enables us to design independently FB and FF control laws for stabilization and response shaping, respectively. FEL is promising in the sense that FF control is tuned on-line and hence can give good response without modeling. For instance, in an experimental work by a former student of our laboratory, an FEL scheme was applied for motion control of a two-link manipulator to write different one-stroke characters. Below, the figure on the left shows the numerical simulation result for writing “8”, while the photo on the right shows the experimental result using the two-link manipulator.
Some FEL schemes turned out to be effective under certain assumptions on the plant; however, if the plant model is plagued by finite zeros, then the conventional scheme cannot overcome the difficulties involved, i.e., risk of over-parameterization and consideration of non-commutative matrix multiplication. This is where my research topic comes in. We propose 2DOF control schemes to deal with the presence of finite zeros in the plant.
Under the guidance of Prof. Kenji Sugimoto, we have published several articles addressing the said topic. One proposed approach is the use of Polynomial Matrix Fractional Representation from the modeling of the MIMO plant to the derivation of the control law to address the presence of finite zeros. Evaluation of the proposed approach is then done via numerical simulation. Based on the evaluation, results prove that the proposed approach is effective and successfully treats the difficulties mentioned above. Aside from this example, other studies, such as the treatment of SISO plants with zeros, are also currently being studied. After evaluating the performance of these feedforward learning schemes, evaluation via experimentation will be explored. One possible application is for vibration control of a flexible link manipulator (shown below) for accurate position control.

Yunduan Cui (D1):
My PhD life in Intelligent System Control Laboratory (ISC lab), NAIST started from October 2014. After finishing Master course, I chose NAIST as my next step because it is a top research university in Japan,that provides me a wonderful research environment. Now I am enjoying challenging research and interesting laboratory life in the peaceful campus every day. My research focuses on develop a new Reinforcement Learning algorithms applicable for high-dimensional and complex robotic systems.
What is Reinforcement Learning? Imaging that we hope one robot to throw a baseball to the target without knowing how to control it. In Reinforcement Learning, we let the robot throw the ball according to its current knowledge (motor skill) firstly (it is obvious that the ball cannot hit the target at the beginning), then we tell the robot how good its performance is (the closer to the target, the better performance) and let it updates its knowledge. In the next iteration, the robot tries to throw the ball again and determine its actions according to the new knowledge. Following this way, after several iterations, the robot will be able to get a quite good knowledge to throw the baseball to the target. This is an overview of RL for robotic systems: making a robot to discover an optimal behavior through trial and error interactions with its environment autonomously.
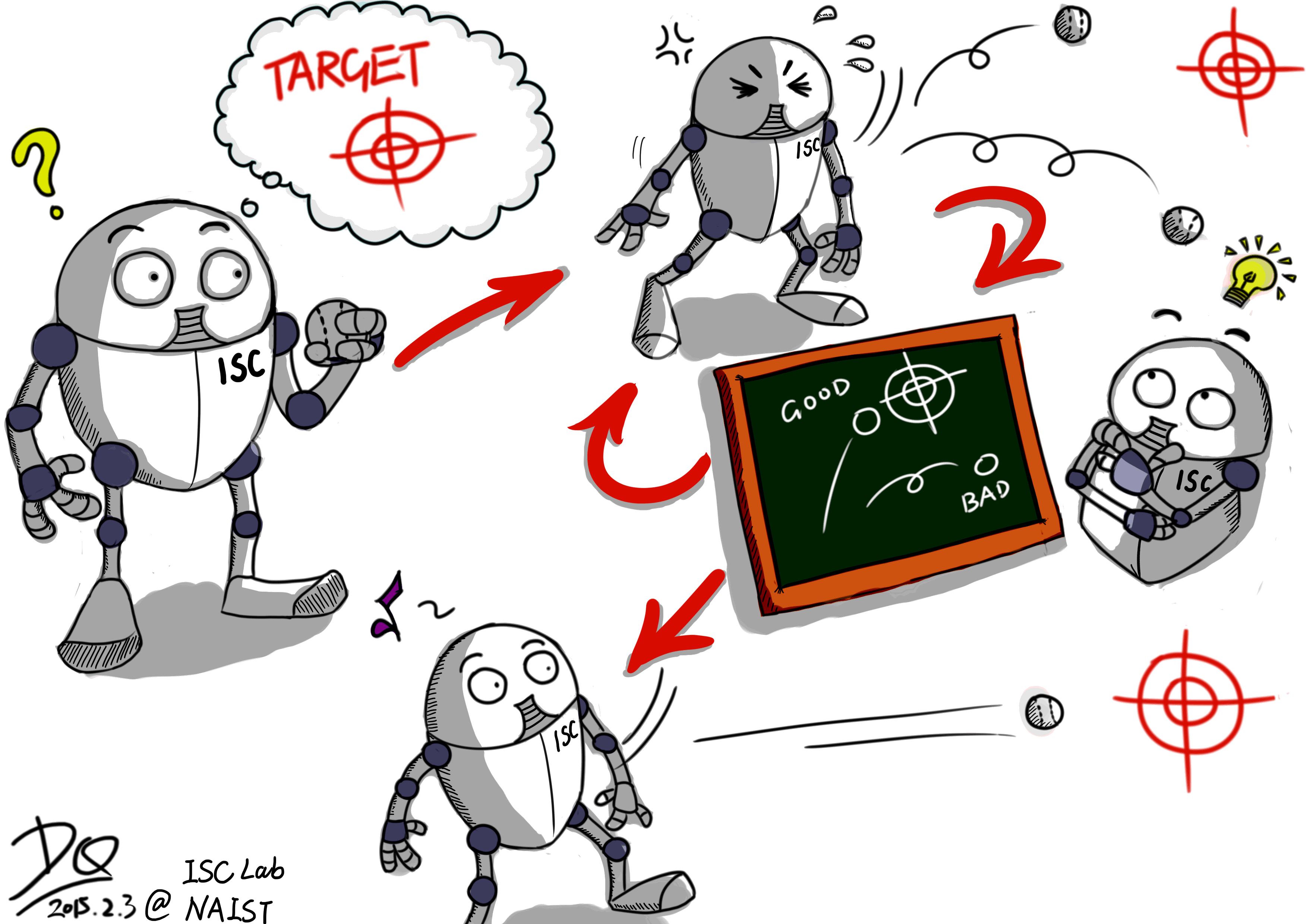
Unlike conventional control methodologies, we do not tell the robot how to do but teach it how to learn by itself. The robot tries to explore an unknown world and learn how to take the action that avoid punishment and get more reward. This process looks like some real animals’ behaviors very much and therefore help us to discover artificial intelligence in a nature way. Thanks to the new advanced machine learning theories and the improved computation ability, RL technologies are progressively popular and practical. They have been applied in more and more complex robotics systems in recent years and had very impressive performance.
In our lab, RL is applied in several challenging tasks with complex robot systems. Different high dimensional robots are trained by RL to solve problems that may be very difficult for other control methods. For examples, helping people put on their cloth, learning something’s shape though touching and even playing table tennis with real people and improving its performance by learning opponents’ behaves.
 RL also provides us a possible way to let the robot to “understand” the real world and therefore becomes more intelligent. Such an amazing feature attracts me so much and encourage me to be a PhD student in NAIST. What we are doing is to make the robot acts like a real animal but not only a cold machine. During my doctor course here, I hope to learn how to be a real researcher with a deep understanding of this field and then make some contributions to it.
RL also provides us a possible way to let the robot to “understand” the real world and therefore becomes more intelligent. Such an amazing feature attracts me so much and encourage me to be a PhD student in NAIST. What we are doing is to make the robot acts like a real animal but not only a cold machine. During my doctor course here, I hope to learn how to be a real researcher with a deep understanding of this field and then make some contributions to it.
