
大規模システム管理研究室では,未来の大規模超並列分散コンピューティング環境のための要素技術やビッグデータ解析に関する研究と,それらの応用として大災害に対するリスク管理やサービス・マネージメントに関する研究を行っています.今回は莫大な規模のサーバマシンから構成されるクラウド・コンピューティングに関するスケジューリング問題を通して研究成果の一端をご紹介します.
クラウド・コンピューティング環境
クラウド・コンピューティングは,莫大な数のサーバマシンを接続して分散コンピューティングを提供する計算環境の総称です.サーバ環境はデータセンター内に構築され,デスクトップPCからタブレットPC,モバイルフォンといった多様な端末がクライアントマシンとしてクラウド・コンピューティングサービスを利用しています.
クラウド・コンピューティングを提供するデータセンターでは,普及品レベルのサーバを増やして処理を並列化することにより,処理性能の向上を実現しています.このようなアプローチをスケールアウトと呼び,現在のクラウド・コンピューティングを支える基盤技術として普及しています.
 スケールアウト型コンピューティング・システム
スケールアウト型コンピューティング・システム
クラウド上で実行されるキーワード検索やビッグデータ解析のような処理では,巨大なタスクを複数のサブタスクに分割し,多数のワーカと呼ばれるサーバマシン上で処理を行う,いわゆる大規模分散並列処理が行われます.Google のMapReduce やオープンソースの Hadoop が大規模な分散並列処理を行うソフトウェアフレームワークとして大変有名です.
キーワード検索を例に取ってみると,非常に大きいサイズ,例えば1TB (=1000GB) のファイルに含まれるキーワードを検索するとき,1台のマシンで検索するよりも,ファイルを1000台のマシンに等分割保存して1台あたり1GBの部分ファイルを検索する方が,探索にかかる時間は単純に1000分の1になります.(並列化のための前処理時間は並列台数が大きくなると増大しますが,それよりも処理時間の短縮効果が大きいときには有効です.)
落伍者の問題とバックアップ型スケジューリング
莫大な数のサーバマシンで並列処理を行うときに問題となるのは,マシン性能のばらつきです.またハードウェアの故障も,マシンの台数が100台,1000台と多くなってくると,無視できない問題になってきます.並列処理ではすべてのサブタスクの処理が完了してタスク全体の処理が完了となります.このような処理では,最も遅いサーバマシンが全体の処理時間を決定することに注意しましょう.この問題は落伍者の問題 (Issue of Stragglers) として知られています.大規模分散並列処理では,マシン性能のばらつきやハードウェアの故障にも柔軟に対応してタスクを高速に処理するスケジューリングが重要な役割を担っています.
ここで簡単な例として4台のサーバで並列処理を行うことを考えてみましょう.
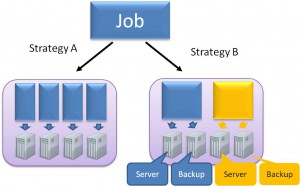
二つのタスク・スケジューリング戦略
次の二つの戦略を考えます.
- 戦略A (上図左側)
タスクを4分割し,4台のサーバで並列処理を行う.4台のサーバの処理すべてが終了した時点でタスク全体の処理が完了.
- 戦略B (上図右側)
タスクを2つのサブタスクに分割し,1つのサブタスクをオリジナルサーバとバックアップサーバの2台で処理をする.オリジナル処理とバックアップ処理で,早く終わった方の結果を採用する.
戦略Aと戦略Bでは,どちらの方がクラウド・コンピューティングでは有利でしょうか?
まず全部の処理が完了するまでの処理時間を考えましょう.1台のサーバでタスク全体を処理するのにかかる時間を1とすると,戦略Aではタスクを4分割しているので1台当たりの処理時間は1/4,うまくいけば1/4程度の処理時間でタスクを完了することが可能です.
一方の戦略Bでは,タスクを2分割しているので1台当たりの処理時間は1/2,うまく処理が行われても1/2の処理時間がかかります.タスク全体の処理時間の短縮を目指す立場からすると,戦略Aの方が分割数が多い分,効果的に時間を短縮できそうです.
次に4台のサーバの内,1台が故障した場合を考えてみましょう.戦略Aでは4台のサーバの処理結果が返ってこないと処理が終了しませんから,故障の場合はタスク処理を完了することができません.一方,戦略Bでは2台に同じ処理をさせていますから,1台が故障した場合でもタスク全体の処理を完了できます.つまり,戦略Bは単純な分割・並列処理と比べて故障に耐性があることがわかります.
それではCPUの性能差や負荷状況によって処理時間にばらつきがある場合,どちらの戦略の方が有利でしょうか?
この問題を考えるためには,戦略Aや戦略Bによるタスクの処理メカニズムを確率的に分析する必要があります.簡単に説明すると,この問題は,複数の確率変数列の最大値がどのような分布に従うかという問題に帰着し,数理的に解析を行うと戦略Aや戦略Bのタスク処理時間の分布を導くことができます.この分析を行った結果,いろいろと面白いことがわかってきました.
まずサーバの処理時間のばらつきが大きければ大きいほど,戦略Bの効果が高いことがわかりました.しかもばらつきが大きいときは並列処理を行うサーバの台数を100台,1000台と増やすほど戦略Bがより効果的になることも判明しました.さらに,ハードディスクの応答が遅くなるなどの中途半端な故障によって処理時間が極端に長くなるような場合には,戦略Bのバックアップ型スケジューリングが効果的であることが明らかになりました.
実装に関する面白い結果として,一つのサブタスクを処理するサーバ数は3台から4台あれば十分であること,5台以上は処理時間がそれほど改善されないことがわかりました.Hadoop では,タスク処理の失敗を見越して他のサーバにタスクを振り直す投機的実行という機能がありますが,この投機的実行の最大回数はデフォルトでは4と設定されています.このデフォルトの値は,分析を通じて得られた結果と合致しており,このような根拠の下で投機的実行の最大回数が設定されていることを改めて認識した次第です.
ここではタスクの処理時間についての話題を紹介しましたが,クラウド・コンピューティングで重要な問題の一つに,データセンターが莫大に消費する電力をどのように削減するか,という問題があります.消費電力という観点から見るとパフォーマンスがよいとされた戦略Bは,サーバを稼働させる時間が全体的に多くなるためにあまりよい戦略とは言えません.クラウド・コンピューティングではタスク処理時間と消費電力量がトレードオフの関係にあり,そのためタスク処理時間を短縮しつつ消費電力量も削減するジョブ・スケジューリング法が重要な研究テーマとなっています.
大規模クラウド・コンピューティング実験システムと始動する研究プロジェクト
大規模システム管理研究室の大きなニュースとして,大規模分散並列処理実験システムがこの度導入されました.HP の MoonShot と呼ばれるシステムがベースになっていて,カートリッジ型サーバマシンを1シャーシで45台収納,1ラックに3シャーシを搭載した高密度型サーバクラスタシステムです.当研究室では全135ノード中100台を専有し,Hadoopが稼働する分散並列処理システムとして実験用に使用します.

大規模クラウド・コンピューティング実験システム
このシステムを使って以下の実験やアプリケーションの構築を行っていく予定です.
- モバイルクラウド実装プロジェクト
クラウド・コンピューティング環境とタブレット端末を高度に連携させたモバイル情報収集分析プラットフォームを構築し,コンテンツデリバリや大規模分散メモリキャッシング,MapReduce型アプリケーション,特に大規模非構造データに対する知識獲得処理を行うアプリケーションを開発します.
- スケールアウトクラウド実測プロジェクト
Hadoop環境において,大規模分散並列処理の性能を実測によって評価を行います.具体的には,ノード数がスケールすることによる処理性能の改善効果やノードの性能をばらつかせることによる処理性能の劣化度合い,タスクスケジューリング方式の性能評価を実機で行う予定です.
- 省電力エネルギー制御プロジェクト
大規模データセンターの電力消費量を抑えつつタスク処理を効率的に行う電源管理スケジューリングを開発します.例えばタスクの到着パターンに適応した電源管理法やタスクの優先クラスによるスケジューリング,サーバ群レベルの電源管理法について検討していきます.
このシステムを使って私たちと一緒に未来のクラウド・ワールドを研究開発していきませんか.