CTやMRIなどの医用画像データは、今やどこの病院でも診断や治療経過の確認のために日常的に取得されていますが、通常手術や治療が終わるとそのまま病院のデータベースに保存され、その後はほとんど使われる機会がありません。また、手術前の血液検査やさまざまな生体計測データ、あるいは手術計画データ、術後のリハビリテーション記録などの多くのデータも同様に、一回限りの使用でお蔵入りとなってしまうのが現状です。
本記事では、私たちの研究室(生体医用画像研究室)で佐藤嘉伸教授の指揮のもと、現在進めている多くの研究プロジェクトの一つの例として、このような再利用される事のない過去の大量の医療関連データ(医療ビッグデータ)を、手術の支援のために活用するシステムの開発について紹介します。このプロジェクトは、平成26年10月に科学技術振興機構(JST)戦略的創造研究推進事業「さきがけ」に採択されました(研究領域:ビッグデータ統合利活用のための次世代基盤技術の創出・体系化、研究課題名:統計学習と生体シミュレーションを融合した循環型手術支援、研究代表者:大竹義人准教授)。
Googleが開発した、膨大な数の検索データからインフルエンザの流行を予測するアルゴリズムや、大量の消費者の航空券の購入価格のデータをもとに、これから買いたいチケットの最安値の時期を予測するシステムなど、ビッグデータは日常生活の中で、広く利用されるようになってきました。これらのシステムでは、個人がインフルエンザに感染するメカニズムや航空券の価格が決定されるメカニズムといった、個々の複雑な現象の全てを解明する事なしに、集積されたデータから直接結果を予測します。このようなシステムを実現している技術は機械学習と呼ばれ、提示されたデータをもとに、機械が法則性を「学習」し、そこで学んだ知識を「予測」に役立てるという仕組みです。結果が分かれば理由は要らない、という新しいパラダイムといえます。このようなデータからの「学習」と「予測」は日常生活で人間が常に行っている作業ですので、このビッグデータの考え方の応用分野は非常に多岐に及びます。
一つの例として、私たちは手術に着目しました。手術中は、術者は五感の全てを使って計測したさまざまなデータ(目で観察して得られる情報、組織を切っているメスからの反力などの触覚、あるいは匂いなど)と、過去に行ってきた手術の経験や患者の病歴、術前に行ったCT検査、血液検査などの「知識」をもとに、現在の患者の状態(出血の度合いや取り残したガンの範囲など)を「予測」し、最善な結果を得るためには次にどのような手術を行うべきかを判断しています(図1)。一方で、このような過去のデータから人体を理解しようという考え方とは逆に、コンピュータシミュレーションの世界では、分子や細胞レベルでの振る舞いをシミュレーションする事で、その集合体である人体全体の振る舞いを理解しようという試みがあります。コンピュータの処理速度の向上により、かなり大きな規模のシミュレーションが可能になってきていますが、人体全体を完全な形でシミュレーションし、手術の結果を予測する事ができるようになるにはもう少し時間がかかりそうです。
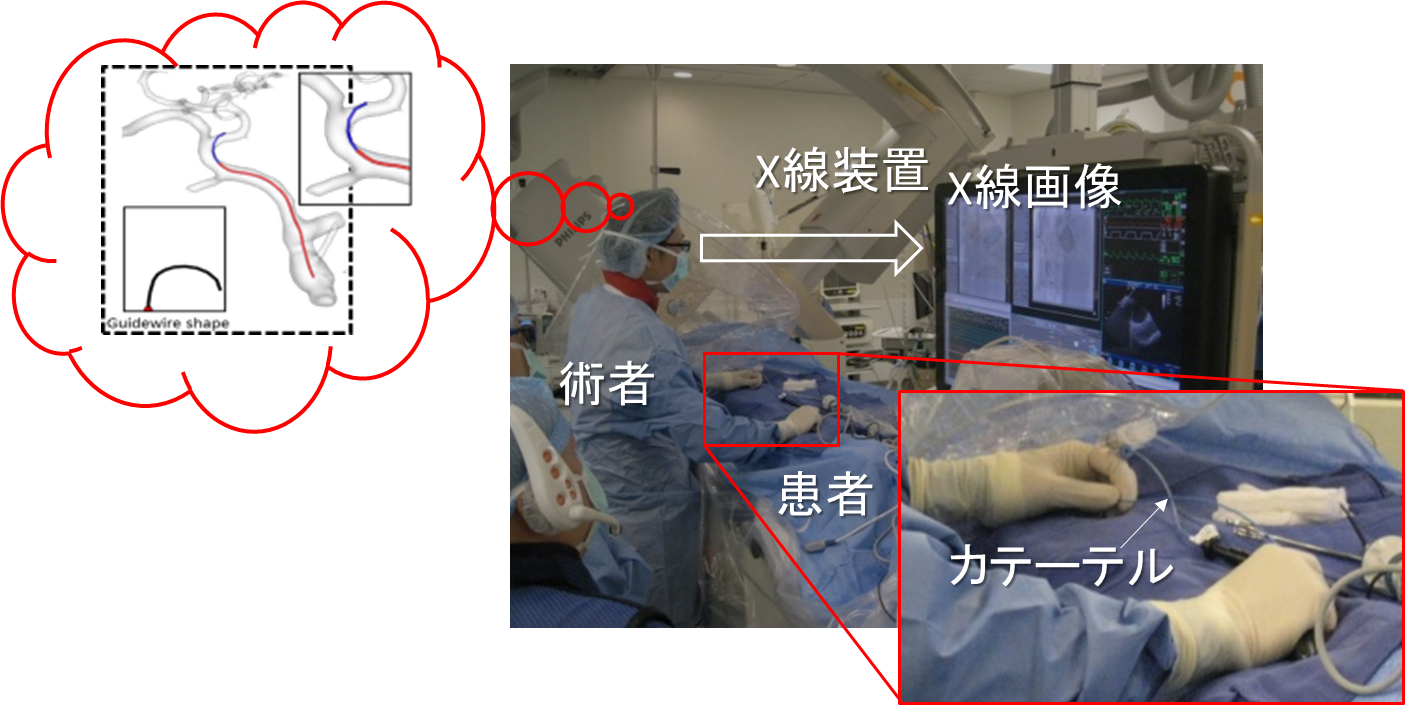
図1 カテーテルを用いた手術の様子。術者はカテーテルから手元に伝わる感触とX線画像から、カテーテル先端の位置を想像しながら手術を進めます。心臓などの柔らかい臓器はX線画像には写らないため、経験や技術を要する難しい手術です。
そこで、私たちが進めているアプローチは、個々の微細構造の機構全てを解明する代わりに、人体全体を大きな一つのシステムとして捉え、このシステムに関する属性データ(性別、年齢など)と加えられた入力(手術、治療)、およびそれに起因して起こる結果(患者の状態、反応)を数多く集積したデータをもとに、人体というシステムの振る舞いを「学習」する、というアプローチです。これは、先に示したGoogle検索データからのインフルエンザの流行予測などのような、大量のデータに基づいて「理由」を解明することなく結果を予測するビッグデータのアプローチに近いものです。例えば当研究室の横田太研究員は、たくさんの過去のCT画像データからいろいろな臓器の形のばらつきを学習することで、新しい患者の臓器形状を、ノイズの多い画像や少ない計測データから予測する研究を行っています。(図2)。
図2 あらかじめ収集したたくさんの被験者の三次元画像(CT画像)から対象の臓器(左図:骨盤、右図:肺)の形状のばらつきを解析した結果。下側の図は、ばらつきの大きな方向に臓器を変形させて表示した様子。
わたしたちが対象としている手術の一つに、心臓カテーテルを用いた心筋焼灼術(心筋組織を小さく焼き切る手術)があげられます。この手術では、二方向のX線動画像(図3左)を参照しながら、カテーテルという細いチューブを太ももの付け根などから挿入し、血管を通って手術対象である心臓まで到達させます。そして、このチューブに針や電極などの手術器具を挿入して治療を行います。この手術を困難にする一番の要因は、心臓の動きです。拍動している心臓内部の目的の部位に正確に針を刺すためには、心臓の動きを「予測」しなければなりませんが、心臓はX線画像には辺縁がかすかに写るだけで、その内部構造を見る事ができません。そのため、術者は、挿入したチューブを持っている手元の感触と、X線画像に写る針の位置やわずかに写る心臓の辺縁の動きから、心臓の三次元的な動き(図3右)を予測し、その動きに合わせて自身の手を動かしながら目標を定め、動きが一番少なくなった瞬間に針を刺します。また、心臓の壁の柔らかさやその動き方は、患者の年齢や性別、疾患程度や体質など、さまざまな要因によって変わってきますので、熟練した術者は過去の経験からこれらの要素も考慮して、手術を進めます。
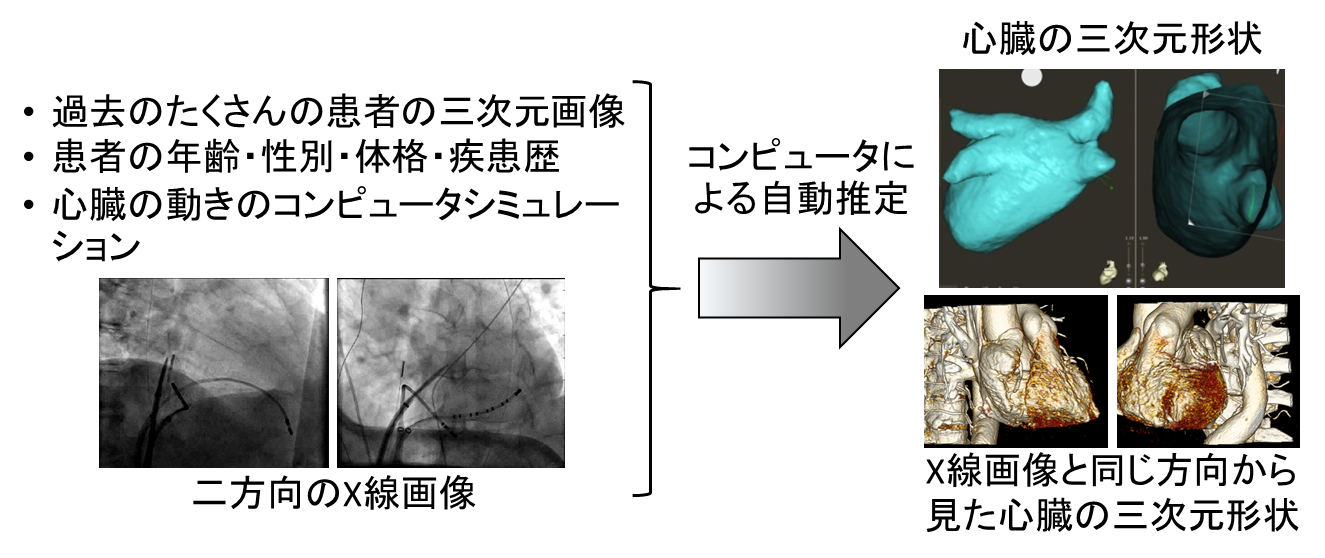
図3 心臓の三次元形状の自動推定。術者が頭の中で行っている過去の患者データからの学習と形状の推定を、コンピュータを用いて自動的に行います。
そこで、この非常に難易度の高い手術を支援するために私たちが開発しているのは、患者の心臓の三次元的な動きとそれに対する針の位置を可視化する、手術ナビゲーションシステムです。手術ナビゲーションは近年、整形外科や脳外科などのような、手術対象が大きく変形しない(剛体に近い)臨床領域では高精度に実現されていますが、対象の変形を予測する事ができていないため、心臓や肝臓などの柔らかい組織では、精度が低下するという課題があります。博士課程三年生の福田紀夫君は前立腺手術の支援のため、術中にリアルタイムに計測される超音波の二次元画像が患者の前立腺全体のどの部分を撮影している画像なのかを、画像に写っている情報だけから(余分な計測機器を必要とせずに)高精度に推定し、術者に提示することのできる新しいタイプの手術ナビゲーションシステムを開発しています。(図4)
図4 前立腺手術用超音波ナビゲーションシステム。術中にリアルタイムに得られる二次元の超音波画像が患者の前立腺全体のどの部分を撮影している画像なのかを、余分な計測機器無しに、画像に写る情報だけから高精度に推定することの出来るシステム。
このシステムでは現在は、前立腺の術中の変形が十分に小さいことを仮定していますが、より高精度なナビゲーションを実現するためには、前立腺の微小な変形を予測する事が必要となります。そこで、私たちは、上で示したような熟練医が頭の中で行っている「学習」をコンピュータで行うことで心臓や前立腺の変形をリアルタイムに予測し、心臓カテーテル手術や前立腺手術をさらに高精度に支援するシステムの実現を目指します。この「学習」をより高精度に行うためには大量の患者に関するデータ、つまり「医療ビッグデータ」が不可欠であり、このために、現在は病院の倉庫に眠ってしまって、再利用される事の少ない膨大なデータベースを用いようというのが今回のプロジェクトです。
生体医用画像研究室では、本記事で紹介した研究以外にも、統計学習を用いた医用画像の領域分け(セグメンテーション)や、位置合わせ(レジストレーション)、あるいは医用画像処理に基づく人体動作の解析など、医用画像を用いた臨床応用システム全般について幅広く研究しています。
ご興味のある方は、研究室のホームページをご覧ください。