
皆さん,こんにちは.コンピューティング・アーキテクチャ研究室 助教の高前田です.
最近,コンピューティング・アーキテクチャ研究室では,受賞やCICPプロジェクトの採択等,喜ばしいことが続いています.
今回は受賞やプロジェクトが採択された方々にお話を聞いてみたいと思います.
博士前期課程2年 田ノ元 正和 (Featured Poster Award @ IEEE COOL Chips 2014)
今年の4月に行われた国際会議IEEE Symposium on Low-Power and High-Speed Chips 2014において田ノ元君のポスター発表がFeatured Poster Awardを受賞しました。
まず、発表した研究内容について教えてください
発表のタイトルは“Performance Tuning of a Global Shallow-water Atmospheric Model on Xeon Phi”で、Global Shallow-water Atmospheric Model Simulation(浅水波方程式を用いた全球大気モデルシミュレーション)を、Intel社が開発しているXeonPhiというアクセラレータ(特定処理を高速化するハードウェア)上でいかにして性能を引き出すかということについて発表しました。あまり詳しくない方にはIntel版GPGPUだと思ってもらえるといいのですが、こういったハードウェアの性能をギリギリまで引き出すにはその特質を理解してコードを記述する必要があります。今回は平方根や除算といった時間がかかる演算の精度をわずかに犠牲にする、メモリのプリフェッチ(先読みによる事前取得)をプログラムの持つ特徴的なアクセスパターンに合わせて最適化するといった手法で性能を出すという方法をとりました。
NAISTに来てちょうど一年ほどでこのような発表をしたわけですが、研究を進める中で大変だったことなどがあれば教えてください
7月ごろまでは研究室内で基礎固めの教育を受け、そのあと9月までFPGAデザインコンテストに出場していたため、実際には10月以降の半年間での成果になります。大変だったこととしてはひたすら実験を繰り返したものの、あまりいい成果が出ない時期が長かったことですね。冬からは就活も始まり両立は大変でしたが、この期間にもあきらめずに取り組んだことで良い成果を得られたので就活ばかりしなくてむしろ良かったと思っています。今回の発表自体も就職面接のネタとして結構使えましたしね(笑)。 就職先選びにおいても、研究での経験が将来のなりたい自分をイメージするきっかけになりました。
もちろん今回の成果は一人の力ではなく、コンピューティング・アーキテクチャ研究室の先生方や先輩、同期、そして共同研究先の中国清華大学の方々の協力あってのものです。特に昨年秋に1か月間清華大学へインターンシップに行かせていただいたのはとても貴重な経験になりました。この研究で協力している清華大学のグループは現在世界1位のスパコン・天河2号を使って先の大気シミュレーションを実行していて、自分の成果が取り入れられるのが楽しみです。
他に感じたこととしては、今回の共同研究やポスター発表、普段の輪講や留学生とのコミュニケーションまで、NAISTに来て以来英語を使う機会がとても多くなりグローバルな大学院だなとあらためて実感しました。
今後は展開などについて教えてください
現在は少し趣向を変えた別分野のアプリケーションの高速化に取り組んでいます。修了までにもう一度対外発表を行いたいと考えています。

博士後期課程1年 Yuttakon Yuttakonkit (CICP (NAISTの学生主導研究プロジェクト) 採択)
Project name is “BikePad: A new experience to control any console game using your bike”.
Goal
Given an increasing awareness of healthcare and fitness in today’s busy society, exergaming (i.e. video games that are also a form of exercise) has gained considerable amount of attention in current game industries. A number of exergaming products nowadays have provided many kinds of workout experiences. However, we have concerned that the existing products are still long way to be considerable equivalent to what we can benefit from the fitness machines. Therefore, we introduce BikePad, a gaming peripheral set that utilizes real bicycles as a gaming input.
BikePad enables players to realistically utilize their own body to throttle, accelerate, turn, and slow down through their real bicycle. Thus, BikePad is possibly the first flexible exergaming peripherals that are considerable with a workout experience on the real exercise machine. BikePad would be able to deliver a dramatically better experience for a wide range of games, especially for the racing type. It is where fitness truly meets entertainment.
Introducing features
BikePad aims to provide enthusiastic workout while playing your favorite game. Additional highlighted features can be also enclosed but not limited to the following list:
- A different way towards virtual workout competition, inherently with multiplayer challenging
- More exciting way for people who are keen on fitness enthusiast to enjoy their workouts through gaming
- Improve social relation between friends and in family
- Reduce chance of accident for a cycle enthusiast to ride indoor when their fitness condition may not meet
- Induce people to get off the couch and be more active
Design and Implementation plan
We have initially selected Xbox as a gaming platform for BikePad, as the Xbox provides sophisticated development kit with some extensible devices such as Kinect. There are multiple device between the bicycle to Xbox console which requires a broaden area of expertise to manipulate the new peripheral device. The hardware design, low-level programming, and some of network sensors will be reviewed and explored in order to inject cycling input into the game console.
While ordinary bicycle static resistant platform called, trainer can replicate outdoor resistant and feel. But it’s not capable to provide all the features and sensors that we can simply adapt for our purpose. Many kinds of sensor technologies are essential to enable a realistically game controlling experience. The sensors that we have investigated so far are velocity (speed), paddle rotation rate (cadence), maneuver, and heart rate.

助教 高前田 伸也 (情報処理学会 研究会推薦博士論文)
今回,情報処理学会の研究会推薦博士論文に先生の博士論文が選出されました.どのような内容の論文なのでしょうか?
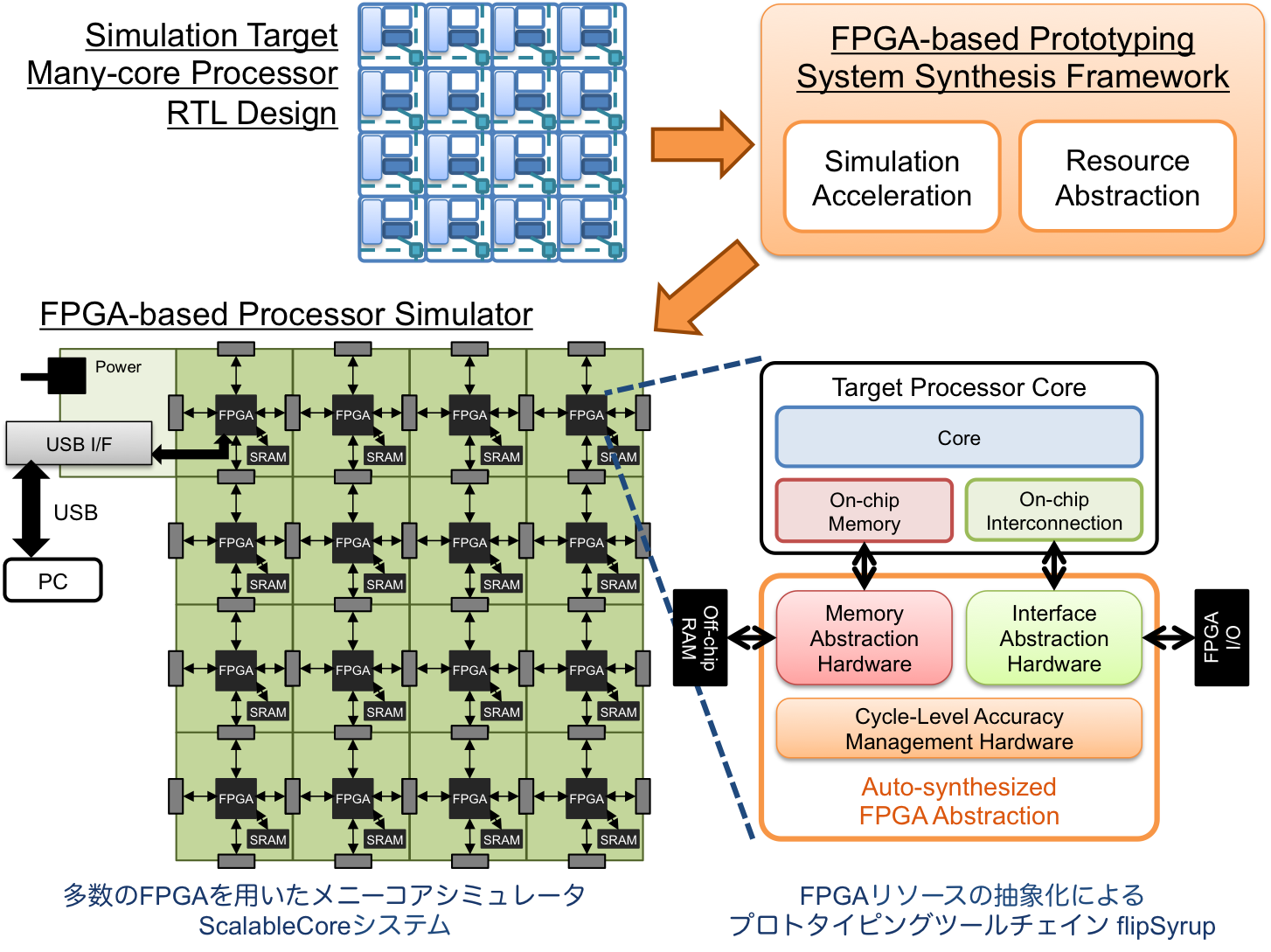
論文のタイトルは”Multi-FPGA based Prototyping Framework for Emerging Manycores”で,内容は,コンピュータの核となるCPUそのものの,ハードウェア・ソフトウェア構成の評価を効率化する高速シミュレーションシステムと,評価対象ハードウェアのモデリングを簡単にするための設計フレームワークに関する研究をまとめたものです.
背景としては,最近のCPUは,パソコンに使われるような比較的大きなものでも,スマートフォンなどの携帯機器に使われる小さなもので,いずれも1つのチップ上に複数のコアを搭載する,マルチコア構成が主流ですよね.今も昔も,半導体プロセス技術の進化によるトランジスタの微細化の恩恵で,1つのチップ・同じ回路面積で利用可能なトランジスタの数は増え続けています.ムーアの法則という言葉は皆さんも耳にしたことがあると思います.以前は,半導体プロセスの微細化により増えたトランジスタを使って,単一のプログラムの処理性能を高めるため,言い換えれば,命令レベルの並列性を抽出するためのハードウェア拡張を行うことが一般的でした.しかし,ポラックの法則で知られるように,仮に2倍のトランジスタを投入して,複雑なハードウェアを追加しても,単一コアの性能は高々1.4程度にしかなりません.そこで,登場したのがマルチコアです.増えるトランジスタを単一のコアの増強に使うのではなく,搭載するコア数自体を増やしてしまうアプローチです.各コアの大きさはそのままで,数を2倍したときに,プログラムが完璧に並列化されていれば,2倍の性能向上が達成できるわけです.そして,最近では,汎用のマルチコアCPUだけではなく,比較的小型なコアを多数集積して並列性能を高めたメニーコアや,超多数のスレッドを同時に実行することで,メモリアクセスなどの実行レイテンシの長い命令のオーバーヘッドを隠蔽するGPU,そして,アプリケーションに特化したデータパス・メモリシステムを形成して高効率化を目指すFPGAなど,様々な計算リソースを扱わなければなりません.
博士論文では,多数のコアを1つのチップに集積するメニーコアアーキテクチャの評価を高速化・高効率化するための仕組みとシステムを提案しています.通常,プロセッサアーキテクチャ研究では,何か新しいアイデアを思いついたとき,ソフトウェアで実現された架空のCPUのシミュレータを用いて評価するのが一般的です.ソフトウェアの世界に,自分がシミュレーションしたいCPUを,クロックサイクルレベルやレジスタ転送レベルという,非常に細かい粒度で振る舞いを定義してシミュレーションすることで,実際にLSIを作成することなく,提案アイデアの有用性を評価するわけです.しかし,そこで問題となるのが,シミュレーション速度です.現存するCPUの上で,架空の将来のCPUをクロックサイクルレベルで正確に模倣するわけですから,実際のLSIと比べると,その速度は非常に低速となります.そこで,用いられるのがFPGA (Field Programmable Gate Array)です.FPGAとは,使う人が回路構成自体を書き換えることができる,柔らかいLSIです.FPGAそのものは汎用のLSIですから,比較的安価に手に入れることができます.FPGAを使えば,一から評価用のLSIをおこすよりも,遙かに安価に,提案アイデアを持つCPUを実際のハードウェア化ができるわけです.このような方式をFPGAプロトタイピングと言います.
しかし,FPGAを用いたプロトタイピングにはいくつか課題があります.ひとつは,マルチFPGAシステムの使いづらさです.シミュレーション対象のCPUの規模がFPGAの回路規模よりも大きな場合には,シミュレーション対象のプロセッサを分割して複数のFPGAにマップしなければなりません.そのときに分割前と同じようにサイクルレベルで正しくプロセッサをシミュレーションするには,FPGA間でシミュレーション情報をお互いに送り合って同期を取らなければなりません.そのためには本来のシミュレーション対象には必要のないハードウェアを追加し,同期ができるようにシミュレーション対象のハードウェアデザインを書き換える必要があります.これがやればいいじゃん?と言うのは容易いのですが,実際に正しく実装するのは結構大変です.また,普通のプロセッサはチップ内にキャッシュなどのメモリ要素を持っているので,これらも一緒に実装する必要があります.FPGAはチップ内にブロックRAMという高速で扱いやすいメモリを持っているので,これを使えばキャッシュ等もシミュレーション対象できます.しかし,FPGAが持つこのブロックRAMの容量というのは限られているので,シミュレーション対象のキャッシュ量を増やしたりする場合には,FPGAチップ外に設けたDRAMなどの大容量メモリを使わざるを得なくなります.そうすると,先ほどのマルチFPGAへの分割のときと同じように,クロックサイクルレベルでのシミュレーションの正確性を保つのが途端に面倒で難しくなります.

博士論文の私の提案は,フレームワークによりFPGAプラットフォームが持つオンチップ・オフチップ両方のメモリシステムとFPGA間の通信を抽象化してしまおうというものです.シミュレーション対象からみれば都合の悪い,FPGAプラットフォーム側のハードウェア要素をすべて,1クロックサイクルでアクセスできる理想的なハードウェアとしてプロトタイプ設計者に提供します.大容量のブロックRAMだったり,直ぐにデータが届くFPGA間通信ポートといった,理想化されたリソースをあたかも使えるものとして,システムを設計できるので,開発が簡単になります.そしてフレームワークが持つツールチェインにより,実際のFPGA上に実現できる回路構成に自動的に変換をします.このときに,オフチップのDRAMやFPGA間通信は実際のものに差し替えられます.同時に,クロックサイクルレベルでのシミュレーション結果の正しさを保証するために,制御用回路を自動で合成し追加します.
評価としては,実際のFPGAプラットフォームで本フレームワークの善し悪しを評価しました.無限大のオンチップメモリを持つ理想的なFPGAが存在したとして,その上での架空のプロセッサのシミュレーション速度と,実在のFPGA上での架空のプロセッサのシミュレーション速度を比べたところ,実際のFPGAを用いた場合のシミュレーション速度は理想的なFPGAのおおよそ半分程度であることがわかりました.つまり,実在するFPGAとオフチップDRAMを組み合わせて作り上げたシミュレーションシステムでも,フレームワークの支援により,開発効率を高めながらも高速に,架空のハードウェアをシミュレーションできるということです.また本フレームワークを用いて,100個のFPGAを接続したマルチFPGAシステム上に128個のコアを持つメニーコアプロセッサを実装し,評価しました.その結果,手動でFPGA間の調停回路等を追加したものと同等の性能を,フレームワークによる抽象化を用いても達成できることが確認できました.
今後の研究について教えてください
これまではFPGAをLSIのプロトタイプとして利用してきましたが,最近はFPGAを用いた高性能計算の方式について研究を進めています.FPGAを使えばアプリケーションに特化した,演算パイプラインをハードウェアとして形成できるので,アプリケーションがうまくハマれば,高い性能だったり,高い電力効率を達成できることが知られています.しかし,FPGA上に計算用回路を構成するためには,一般的にVerilog HDLやVHDLといったハードウェア記述言語でクロックサイクルレベルですべての振る舞いを定義しないといけないのですが,これが結構大変です.どれくらい大変かというと,ソフトウェア開発に例えれば,アセンブリ言語だけを使ってソフトウェアを開発するのを想像して貰えればわかると思います.これを解決するための方法として,C言語やJavaなどの一般的なプログラミング言語で記述したソースコードをハードウェア記述に変換する,高位合成コンパイラというものが登場し広まりつつあるのですが,簡単なアプリケーション以外では性能がイマイチだったりと,まだまだ発展途上です.
そこで現在,高い性能と開発効率の両立を目指して,高位合成技術として,メモリシステムの抽象化を用いた,設計のポータビリティと性能を両立するFPGAアクセラレータの開発フレームワークPyCoRAMというものを開発しています.性能にクリティカルな演算パイプラインは従来のHDLでモデリングしつつ,メモリやI/Oといったアクセラレータの外とのやりとりは,スクリプト言語のPythonを用いた高位合成処理系で開発することで,開発効率と性能を両立します.アプリケーションとしては,密行列積やステンシル計算といった,高性能計算の王道的なアプリケーションだけではなく,グラフ処理などの今ホットなアプリケーションを開発し,FPGAを用いた計算機システムの可能性を追い求めています.

以上,コンピューティング・アーキテクチャ研究室からでした.長文失礼しました.
見学・インターンシップ等は随時受け付けております.コンピュータの高速化・低消費電力化・高信頼化に興味のある方,お待ちしてます!
Facebookページもよろしくお願いします!
文責:高前田 (shinya_at_is_naist_jp)