
自然言語処理学研究室 教授の渡辺です。自然言語処理学研究室では、自然言語の構文構造や意味を解析し、知識を自動的に抽出するといった研究をしています。また、機械翻訳や画像キャプション、要約など、文章や画像を入力として別の文章を生成したり、文法誤りの訂正など言語習得の支援などの研究を行っています。
NAIST Edgeでは最先端の研究を紹介する、ということですので、今回は固有表現を含む、名詞句の抽出技術について紹介したいと思います。固有表現は、人名や地名などの固有名詞や日付、時間などでして、このような表現をテキストから自動的に抽出するタスクは検索や質問応答などさまざまな自然言語処理のアプリケーションに利用されています。辞書があれば簡単にできるのでは、と思われますが、知識は日々更新されていますので、新しいニュースや科学技術論文が出るたびに辞書を更新するのは現実的ではありません。また、単純に名詞句を並べただけでは、と思われがちですが、GENIAコーパスと呼ばれる、生命科学の分野を対象とした論文のアブストラクトのデータを眺めますと「Employing the [EBV – transformed [human B cell line] ] SKW6.4 , we demonstrate …」のように入れ子構造になったものや「prostate cancer and brest cancer cells」などのように、並列構造になったものがあります。特に並列構造では、この例のように「prostate cancer cells」から「cells」が省略され、解析を難しくしています。単純に「and」があれば並列にすれば良い、というものではなく、「Nara Inatitute of Science and Technology」のように、「Science」と「Technology」が並列ですが「NAIST」全体で一つの固有表現になります。
この問題に対してよく使われているのが「系列ラベリング」という手法です。例えばある入力文「… an increase in Ca2+ -dependent PKC isoforms in monocytes」に対して、下図のように、各単語にBおよびI、E、Oといったラベルを割り当てる、というものでして、各ラベルがそれぞれ「開始」「内部」「終了」「固有表現以外」のラベルになります。この例の場合「Ca2+ -dependent PKC isoforms」が固有表現になります。深層学習の技術を用いることで、テキストの各単語に対してラベルを予測する問題、として考え、このようなラベルが付けられた学習データからモデルを学習できます。ところがこの手法では、学習データが存在することを前提としていまして、科学技術の全ての分野でそのようなデータが存在するとは限りません。また、並列構造を発見するためには複雑なラベルを割り当てる必要があります。
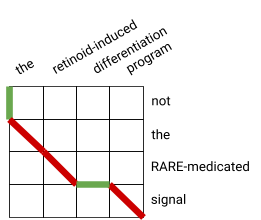
計算言語学の国際会議COLING 2020で本研究室の澤田が発表した、名詞句の並列構造を解析する手法では、特定の分野の学習データがなくとも、高精度に解析できることを示しました。本研究では、並列構造を取る名詞句は意味的に近いだろうと仮定し、まず、文の中で並列構造を取りそうな単語列を全て列挙します。その後でfastTextやELMo、BERTなどを利用して、各単語のベクトル表現を求め、単語単位のペアに対して、意味的に近いかどうかをベクトル間の距離により計算します。さらに単語列単位の近さは動的計画法に基づいた編集距離で求めます。右の図の例では、「the retinoid-induced differentiation program」と「not the RARE-medicated signal」との近さを計算しています。この例では、「the ↔ the」および「retinoid-induced ↔ RARE-medicated」「program ↔ signal」が近いと計算され、対応付けられていますが、「differentiation」および「not」が対応付けられていません。この手法により、ラベル付き学習データにより訓練されたモデルに匹敵する性能で並列構造を解析できます。
計算機でも処理しやすい論文は人間でも読みやすい論文でもあります。たとえ冗長になったとしても、専門用語を複雑に組み合わせるような構造をなるべく避けるよう心がけてください。複雑な構造が増えると私達の仕事が増えてしまい、困ってしまいます。