
奈良先端大知能コミュニケーション研究室准教授の須藤です.今回は当研究室で開発している授業アーカイブ自動翻訳システムと,そこで用いられている深層学習の技術について簡単に紹介します.
プレスリリース:日本語授業映像に付ける英語字幕をAIで自動作成 深層学習技術活用のシステムを開発 ~留学生らの自習支援など国際化に期待~
大学教育の国際化の進展と留学生の増加により,情報科学領域でも約半数の授業は英語で行われています.日本語で行われる授業については英語のスライド資料を利用するなどしていますが,日本語が分からない学生は資料だけで授業内容を理解しなければなりません.他方,本学では講義室の授業映像を録画・保存し,学内で閲覧できる「授業アーカイブシステム」を運用しています.私たちは,知能コミュニケーション研究室で取り組んでいる技術によって日本語の授業を英語に翻訳し,授業アーカイブシステムで字幕として見せることで日本語が分からなくても授業アーカイブシステムを用いて復習・自習できるような仕組みを作っています.日本語および英語の字幕が表示された授業アーカイブはこのような画面で表示されます.
このシステムは,授業で話される日本語を文字起こしする「音声認識」と,日本語を英語に自動的に翻訳する「機械翻訳」の二つの技術で実現されています.それぞれ長い歴史を持つ技術ですが,最近の深層学習(ディープラーニング)技術によって大きく性能が向上しました.今回は須藤の専門である機械翻訳(コンピュータを用いて自動的に翻訳を行う技術をこう呼びます)の技術を紹介します.
深層学習技術で用いられる計算の仕組みをニューラルネットワークと呼びます。詳細な説明は省きますが、ニューラルネットワークでは単語や音声、画像といった処理の対象をすべて数値を使って表します。数値といっても一つの数ではなく、数百個の数を使ったベクトルという形で表します。模式的な例として、X軸・Y軸を用いた2次元の平面で単語を表した例を次の図に示します。
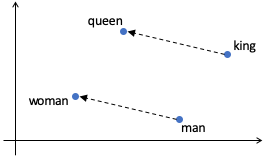
この図では、man、woman、king、queenという単語が、2次元の平面上の別々の点として書かれています。それぞれの点には対応するX,Yの2つの数があり、この例では2つの数を使って単語を表現していると言えます(実際の研究では500次元、1000次元等より複雑な空間を使います)。さらにこの図では、manとwomanを結ぶ矢印つきの線とkingとqueenを結ぶ線がとてもよく似ています。このmanとwomanを結ぶ線は、manの座標をv(man)、womanの座標をv(woman)と表すとv(woman) – v(man)と書くことができます。それを使うとqueenの座標 v(queen) がkingの座標 v(king)を使ってv(king) – v(man) + v(woman)と表すことができるのです。実際には多少誤差があって完全に等しくなることはないのですが、単語をベクトル(座標)で表すときの例としてよく用いられます。
ニューラルネットワークを使った機械翻訳のことをニューラル機械翻訳と呼びます。単語を数で表現する考え方を上で説明しましたが、ニューラル機械翻訳では一つの単語だけでなく、複数の単語の並びや文もベクトルで表現します。ニューラル機械翻訳の処理を非常に単純に表現した図を以下に示します。
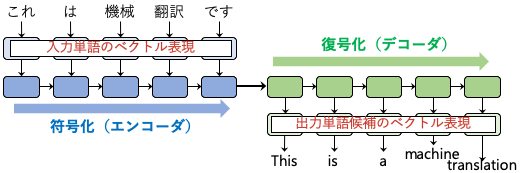
日本語を英語に翻訳しようとするときに、まず日本語の単語をベクトルに変換して、そのベクトルを一つずつコンピュータに読み込ませます。読み込ませるときには、今持っているベクトル(左下の青い四角)と新しく読み込むベクトル(「入力単語のベクトル表現」と書かれたもの)にある決まった計算をして、新しいベクトルを求めます。例えば、「機械」という単語を読み込み終わった時点では、そのベクトルは「これ」「は」「機械」という3つの単語を読み込んで記憶できると考えてください。すべての単語を読み込み終えると、今度は英語に翻訳した文を出すために、英語の単語を一つずつ読み出します。読み出す仕組みもベクトルを用いた計算によるもので、ベクトルにある決まった計算をして、英語の単語に対応するベクトルと、これから出力する単語の情報を持つベクトルの二つを得ます。この処理を繰り返して、単語に対応するベクトルを一つ一つ単語に変換することで、最終的に英語の文が得られるというわけです。
上の説明で「決まった計算をして」と書きましたが、当然正しい結果が得られるように計算をする必要があります。ベクトルの中の数に対する掛け算や足し算を組み合わせて、ベクトルから別のベクトルを得るような計算をするのですが、ここでどういう数(パラメータ,と呼びます)を掛けたり足したりすれば正しい結果が得られるのか、を対訳(異なる言語の同じ意味の文の組,例えば日本語と英語)を使って調整するのです。その方法の詳細はここでは説明しませんが、最初はランダムな値から始め、正しい翻訳結果が出てくるようにするにはこのパラメータの値を大きくすればよいのか、小さくすればよいのか、を調べながら、少しずつ調整をしていくのです。
このようにして、機械翻訳や音声認識は大量のデータを使って、正しい結果が得られるパラメータの値を「学習」することで実現されています。このようにデータから何かの問題の解き方をコンピュータが身につけるための技術を「機械学習」と呼びます。機械翻訳や音声認識はその一例ですが、最近のコンピュータはそうした技術によって様々なことができるようになってきているのです。