Hi, everyone! This is Yuanyu Zhang from the Large-Scale Systems Management Laboratory. It is a great opportunity for me to share my research with you. Broadly speaking, my research focuses on the security of Internet of Things (IoT) systems, with special interests in securing IoT wireless communications based on physical layer security (PLS) technology and designing access control schemes based on the emerging blockchain technology. Now, I am going to briefly introduce my research from these two aspects.
-
PLS-based Secure IoT Wireless Communications
When it comes to the IoT, I believe anyone can give an concrete application, such as smart home, e-health, intelligent transportation, etc. In these applications, a huge number of smart devices, like sensors, actuators, tablets, will be connected into the Internet via a variety of wireless communication technologies, like WiFi, Zigbee and Bluetooth. As we all know, wireless medium is open such that anyone close to a transmitter can receive its signals. Suppose the information conveyed by the signal is not encrypted, so what would happen if the signal is received by an eavesdropper? Obviously, the information is in danger! In IoT applications, these information may be your health data perceived by sensors around you and your financial transfer records sent from smart phones. Once these information are leaked to eavesdroppers, your life and property will be in danger.
Of course, we can encrypt these information using secret key-based cryptographic approaches like what we do in wired communications. However, managing and distributing secret keys in wireless environment is challenging, especially for large-scale IoT systems. Besides, the cryptographic approaches usually require high computing power, which is unavailable for most resource-constrained IoT devices. This motivates the advent of the so-called physical layer security (PLS) technology, which uses the inherent randomness of wireless channels (e.g., fading, noise, interference) instead of costly cryptographic approaches to ensure no information leaked to eavesdroppers. As long as we can guarantee that the received signal of the eavesdropper is an degraded version of that of the intended receiver, the eavesdropper can abstract nothing from the signal. This conclusion has been proved from the perspective of information theory. The figures below shows the basic differences between cryptographic approaches and PLS technology.
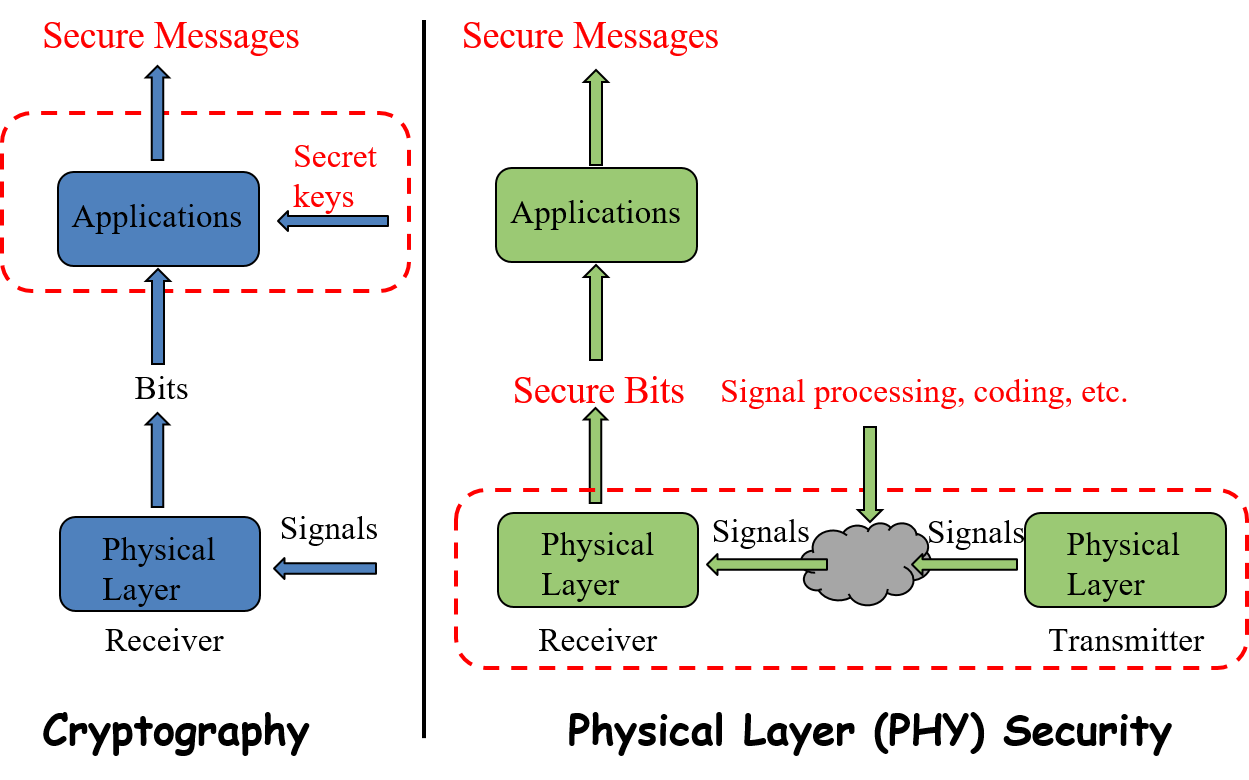

What my research does is to apply commonly-used PLS techniques in IoT systems and theoretically evaluate the security performances of these systems using some mathematical tools, like Probability Theory, Markov Chain Theory, Queuing Theory and Stochastic Geometry. Well, okay, I know it’s boring, but trust me, it is vitally important for understanding the PLS performance limits of IoT systems and contributing to the successful application of PLS techniques in these systems. If it does not sound boring to you, I would be very glad to share this research with you in greater details.
-
Blockchain-based IoT Access Control
Okay, ready for another research? You know what, this research may be more interesting, at least for me. The previous research focuses on the security of the information during its transmission, while this research focuses on the security of the information when it is stored somewhere as resource and accessed by some users or devices. Of course, resources are not limited to information, but also include actuators that may perform some critical tasks, like brake control and drug delivery. But one common thing is that, once these resources are accessed by malicious users, your life and property will be in danger. This research aims to design effective access control schemes to prevent illegal access to IoT resources.
Traditional access control schemes are centralized, which means that they use a central server to control all access requests in the system. So what if this server is destroyed in disasters, or what if this server is compromised by some malicious guy? Yes, the whole access control scheme collapses. Now, question is how to tackle these challenging issues. Fortunately, the emerging blockchain technology provides us with a promising solution, because it is highly distributed and ensures reliable financial transactions among trustless peers all over the world. In this research, I use the Ethereum blockchain, which evolves into a distributed and reliable computing platform thanks to the introduction of smart contract. A smart contract can be thought of as a piece of code that is stored on the blockchain and distributed to all nodes in the system. All nodes can execute this code and verify the correctness of the results. This ensures the correct execution of the smart contract as long as no one possesses more than 51% of the system computing power.
The basic idea of this research is to ensure distributed and reliable access control by expressing the access control policies and logic as smart contracts. The access control framework is illustrated in the figure below.
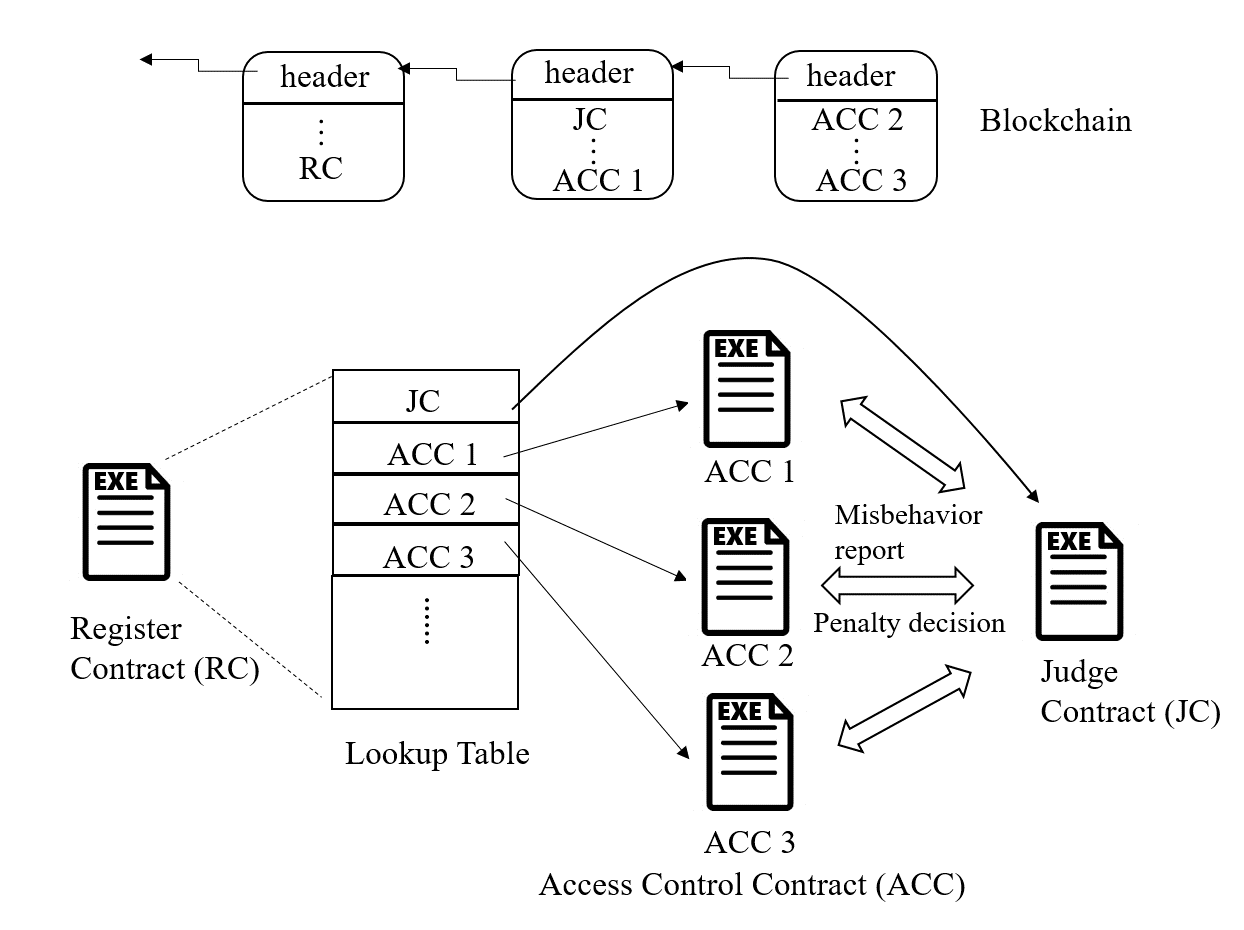
This framework consists of multiple access control contracts (ACCs), one judge contract (JC) and one register contract (RC). Each ACC is responsible for the access control of a subject-object pair, and implements both static access right validation based on predefined policies and dynamic access right validation by checking the behavior of the subject. Here, a subject is the node accessing the resources possessed by an object. The JC implements the misbehavior-judging method to facilitate the dynamic validation of the ACCs by receiving misbehavior reports from the ACCs, judging the misbehavior and returning the corresponding penalty. The RC registers the information of ACCs and JC, and also provides functions (e.g., register, update and delete) to manage these methods. Suppose a server wants to access the resource of a camera in a smart home. The workflow of the access control is shown in the figure below.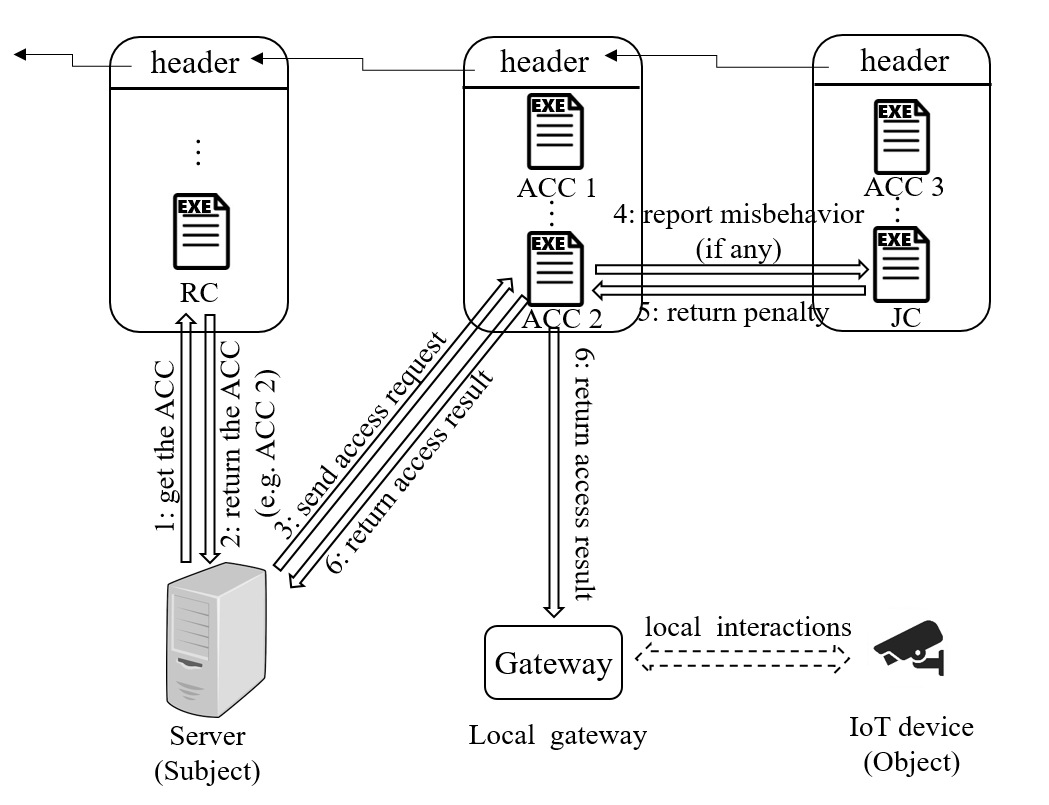
- Step 1: The server calls the RC to retrieve the ACC (e.g., the ACC 2) for access control.
- Step 2: The RC returns the address and ABI (similar to API) of the ACC to the server.
- Step 3: The server sends a transaction to the ACC, which contains the required information for access control. This transaction will be encapsulated in a new block and the ACC will not be executed until the new block is mined and included in the blockchain by some miner.
- Step 4: During the access control process, the ACC will send a message to call the JC, if some potential misbehavior of the subject is detected.
- Step 5: Once the JC judges the misbehavior and determines the penalty, it will return the penalty to the ACC.
- Step 6: Finally, the access result will be returned to both the subject and object, after the access control process finishes.
To demonstrate the feasibility of the framework, we provide a case study in an IoT system with one desktop computer, one laptop and two Raspberry Pi single-board computers, as shown in the figure below.

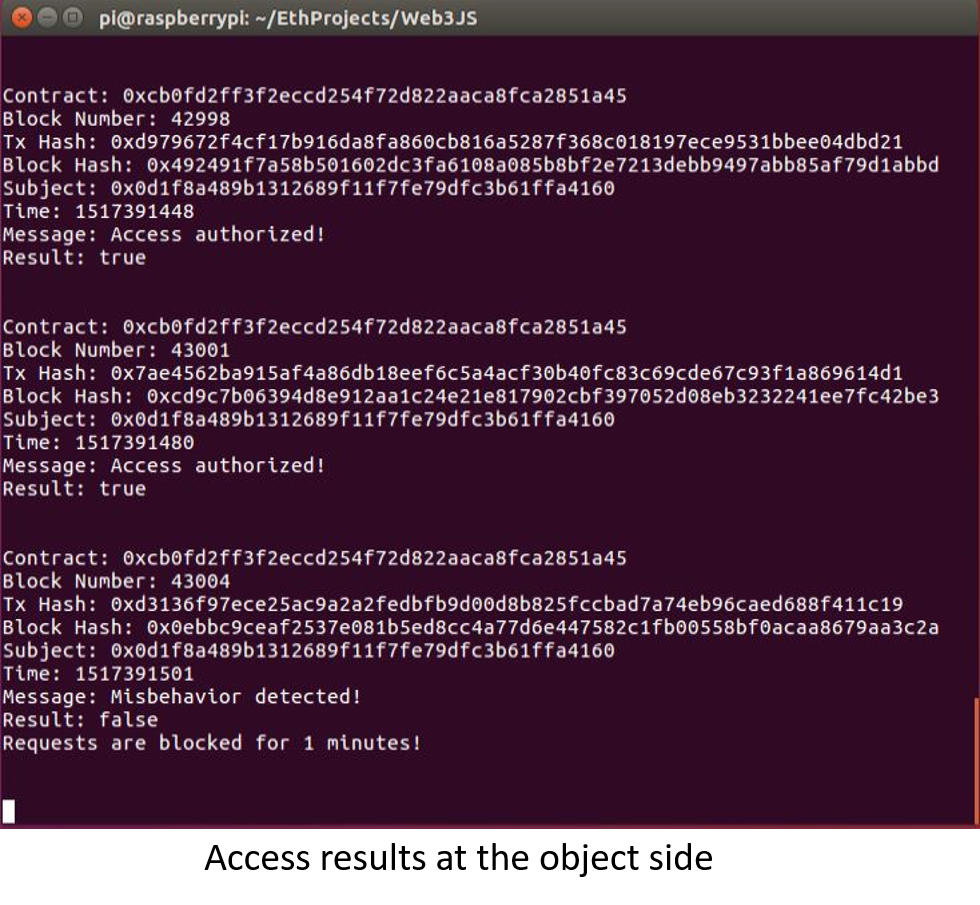
And the results of access control at both the subject and object sides are illustrated in the figures below.