
知能コミュニケーション研究室助教の品川政太朗です。知能コミュニケーション研究室では、音声機械翻訳や対話システムなど、人と人、人と機械のコミュニケーションを支援する技術についての研究を進めています。コミュニケーションを重視しているということで、話し言葉を中心とした音声処理や言語処理、表情や身振り手振りなどのパラ言語情報を扱うための画像処理など、さまざまな情報処理を扱っています。
私が注目しているのは、言葉を使って、機械が人間とコミュニケーションをとりながら問題を解決するような課題です。現在は特に新しい画像の生成を行う対話システムの研究に取り組んでいます。画像生成は、近年著しく技術が進歩している技術です。広告やイラストの作成には高い技術が求められる上に、非常に手間がかかります。このような画像を自動的に生成できれば(または、実際に商用利用できる程でないにしろ、そこそこ良い画像を思い通りに生成できるようになれば)広告やイラストなど、画像の作成を専門にしている方が補助的に利用したり、画像を作成する技術がなくても、自分の欲しい画像の大まかなイメージを専門家に伝えたりなどして、コミュニケーションの齟齬を減らすことが可能だと考えています。よりイメージしやすい身近な例としては、探し人や探し物がある場合に、言葉で伝えるよりも画像を共有しながらお互いが頭で考えているイメージを擦り合わせていくことで、探し人や探し物を効率的に見つけるといったことができると考えています(図1)。
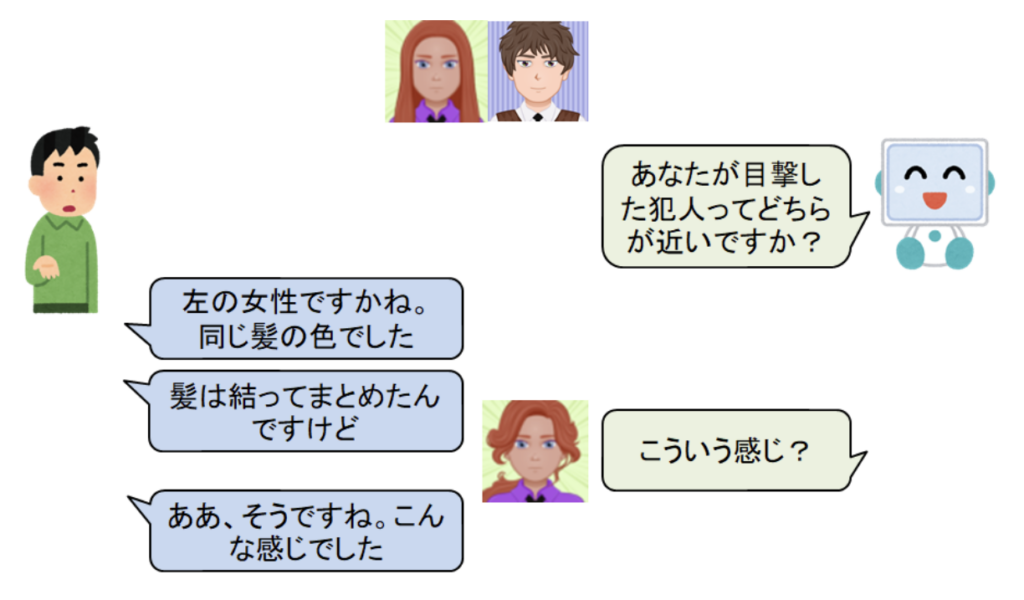
このように、画像情報と言葉(言語情報)を組合わせて問題解決をするという研究分野は、まとめてVision & Languageと呼ばれており、世界的に盛り上がりを見せている研究トピックの一つとなっています。言葉でコミュニケーションをとれる、という要素は、将来的に機械が人間の役に立てる範囲を拡大するために、重要な要素だと考えられています。人間にとって最も頻繁に用いられる情報伝達の手段は言葉(言語情報)です。機械が言葉を理解し、扱えるようになれば、様々な作業を機械に言葉で頼むだけでできるようになる利点があります。
一方で、言葉というのは多様な表現が許されます。また、個人によっても、同じ言葉でも意図が異なる場合があります。たとえば、「この画像を格好良くしてほしい」というお願いをユーザが行った時、「格好良い」に紐づいている具体的な結果のイメージは、人によって様々です。人間同士の場合は、このような場合に「あなたの言う格好良いとはこういうことですか?」などと聞き返したり、対話することによってお互いの意図の擦り合わせを行えます。私は、このような対話の能力を機械が得られるようにし、個人に合わせて問題解決を行う機械を作りたいと考えています。
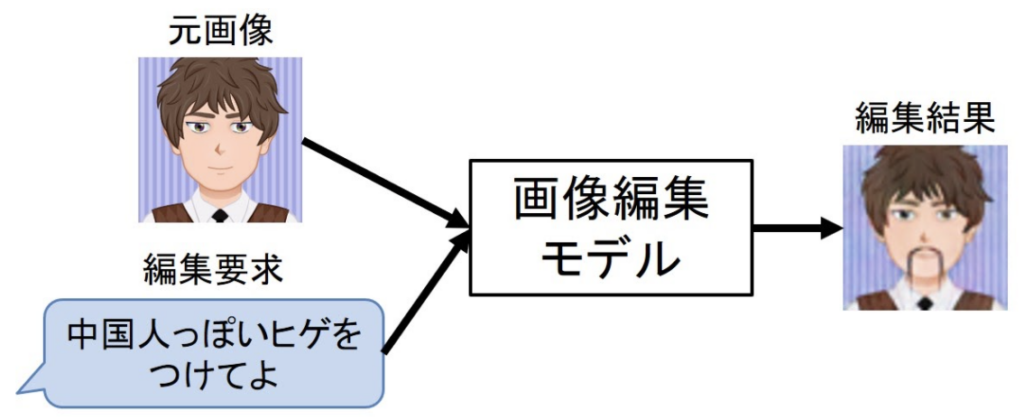
深層学習による、元画像と編集要求の文から目的の画像に編集するニューラル画像編集モデル
今回は、私の博士での研究と、その展望について簡単に紹介したいと思います。私が行った研究は、まさに図1にあるような、ユーザが言葉を使って、ユーザの思い浮かべている画像に向かって、段階的に画像を編集するシステムの研究です。編集する方法には、深層学習という方法を用いています。ニューラルネットワークという用語でも有名かと思います。深層学習では、画像と言葉のように、異なる情報源をベクトルとして表現し、ニューラルネットワークと呼ばれるネットワークを利用して、画像と言葉のデータからその対応関係を結びつけることができ、これを利用して、編集元の画像(元画像)と編集要求の文から、目的の画像への編集を行っています(図2)。
具体的には、画像を編集するのに向いている、敵対的生成ネットワーク(Generative Adversarial Networks; GAN)というニューラルネットワークを利用しました。編集要求の文の情報は、時系列情報を抽出するのに向いているLong-short term memory (LSTM)、編集対象の元画像の情報は、画像情報を抽出するのに向いているConvoluation Neural Networks (CNN)というニューラルネットワークを利用しました。元画像と編集要求の文の情報を組合わせて、GANで生成するという仕組みです。
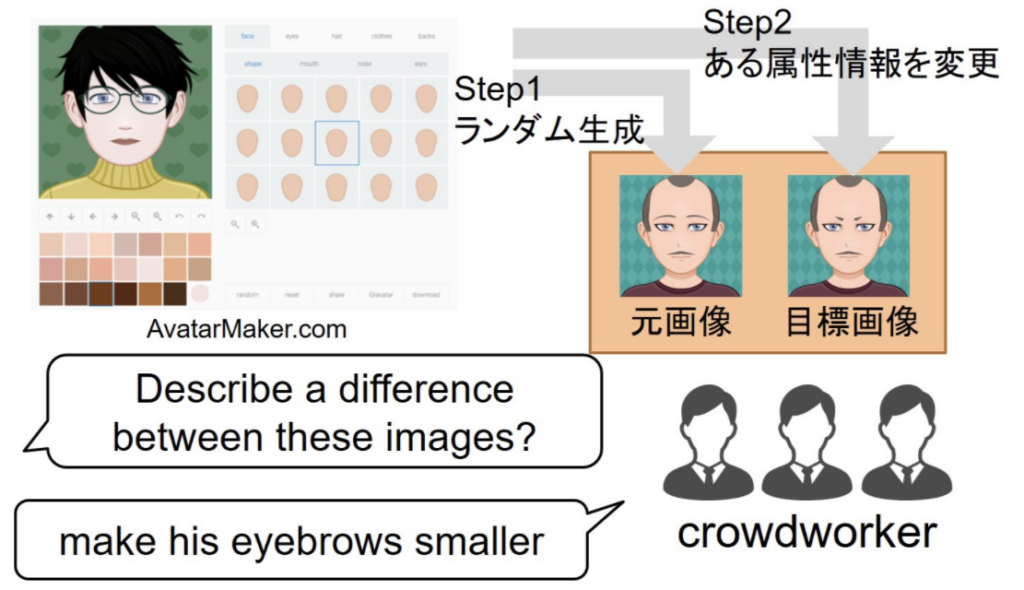
このモデルを学習するには、編集前の元画像、編集後の目標画像、そして両者の変換に対応する編集要求の文の3つの組で構成されるデータが必要になります。このようなデータはこれまでに存在しなかったので、アバター画像の作成が可能なウェブサイトを利用して、少し異なる画像の組をつくり、それぞれ元画像、目標画像とし、これらの画像の組をクラウドワーカーに見せて、2つの画像の違いを言葉で表現してもらいました(実際には英語を利用しています)(図3)。
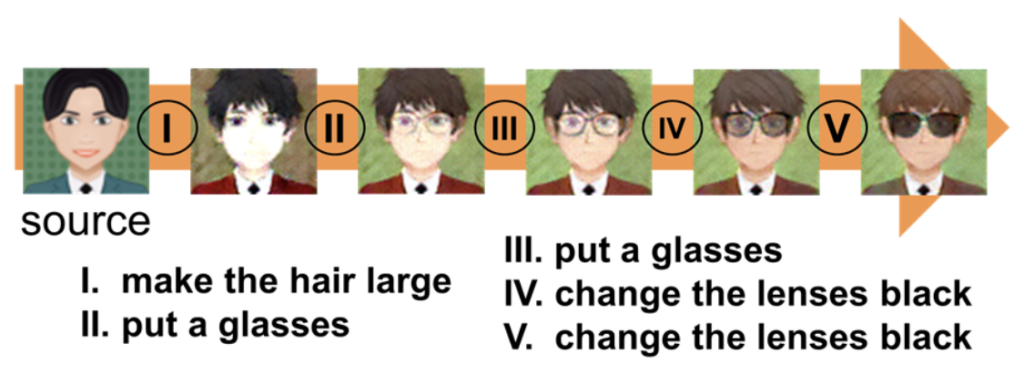
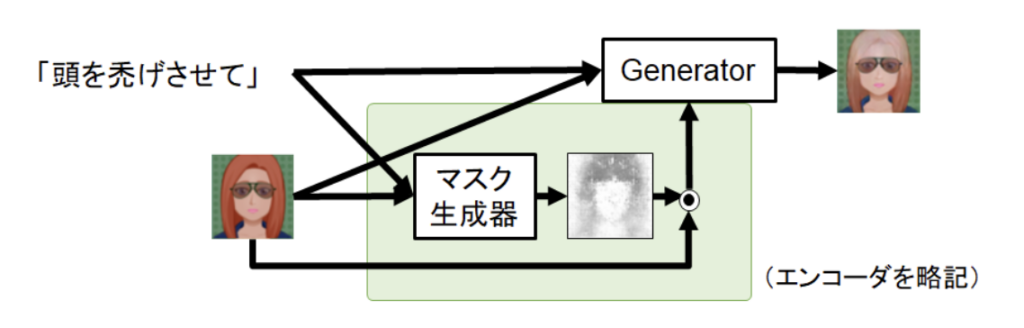
実際に画像編集モデルを学習させてみると、面白いことが分かりました(図4)。確かに入力である編集要求の文に沿った編集はできているものの、要求していない部分まで編集されてしまいました。多様な表現が許される言葉と画像の編集操作を結びつけることは、簡単にはいかなかったのです。この新たな問題に対して、本研究ではさらに、元画像のどの部分が編集するべき領域なのかを明示的に分けるマスク機構を提案して、マスク機構なしの場合より優れた編集が可能であることを明らかにしました(図5)。
システムからユーザへの確認戦略の導入
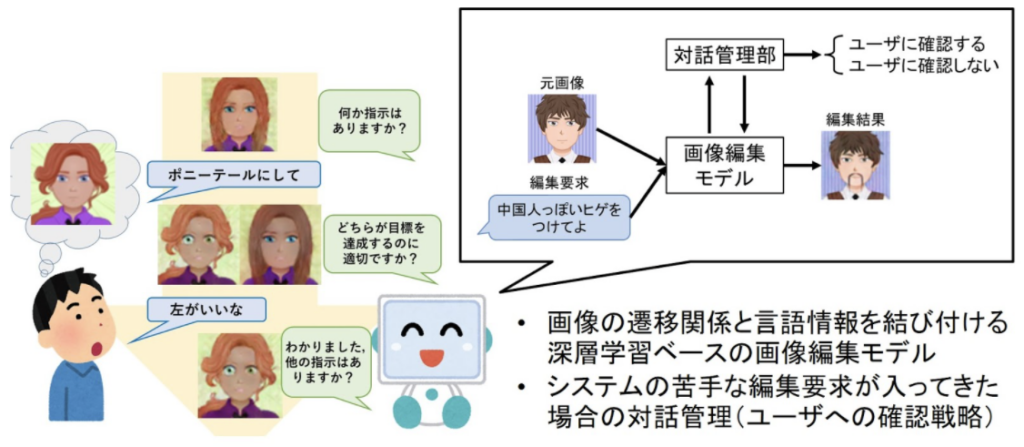
もう一つの研究は、システムが自信がない時に、ユーザに対して確認を行うという対話戦略をシステムに取り入れて、対話的に画像を編集するという研究に取り組みました。ユーザの多様な要求には、システムが苦手にしている入力も当然含まれます。深層学習のモデルは、限られたデータセットを用いて学習されるため、一つのモデルで多様な入力のすべてに対応することは困難です。例えばマスクありモデルは、髪の毛など大きな領域の編集を苦手としています。そのような場合に、複数のモデル(マスクあり・なし)による出力をユーザに見せて選んでもらい、より目標を達成できそうな方の画像を選んでもらうという対応策が考えられます。かといって、毎回確認するのはユーザの負担となります。そこで本研究では、生成されたマスクのエントロピーを基準として、必要な時だけユーザに確認することで、冗長な対話を削減できることを明らかにしました(図6)。
今後の展望
本研究では、「ユーザが言葉で画像を編集できる」という点に注目して研究を進めてきましたが、現実的に役に立つものを実現するには、まだまだたくさんの課題あります。例えば、実際のユーザは、一部なら自分で絵を描いたりできるかもしれません。言葉だけでなく、他の入力方法も考慮することで、どのような時に言葉を使うのが有用であるのか、明らかにしていく必要があります。また、どの編集も気に入らなかった場合に、どのようにユーザに働きかけると、ユーザにとって好ましいのかも、明らかにしていく必要があります。そして、言葉は本来、ユーザの文化的な背景などによって、指す意味が異なることが自然です。よって、対話を通して個人に適応するといった要素も必要になってきます。これらの面白い課題を一つ一つ解決していき、機械が様々な課題で人間とコミュニケーションをとりながら、より人間にとって心地よく、問題を解決できるような方法を模索していきたいと考えています。
著者紹介
品川 政太朗(しながわ せいたろう)
札幌出身。東北大学で学士・修士を取得後、博士後期課程から奈良先端大知能コミュニケーション研究室に所属。2020年9月に博士(工学)を取得後、現在は同研究室の助教として対話班を主導している。専門は画像と言語を組合わせて問題を解決するVision & Languageという分野で、特に対話的なコミュニケーションを行えるシステムの研究に従事。
🔗 Webサイト:
https://seitaroshinagawa.github.io/
