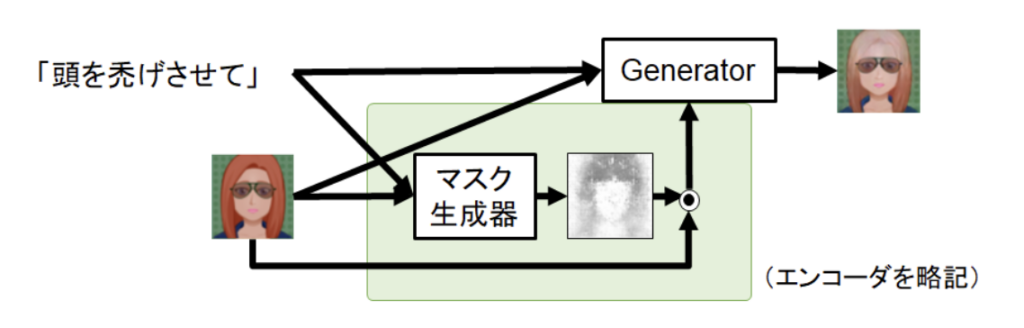
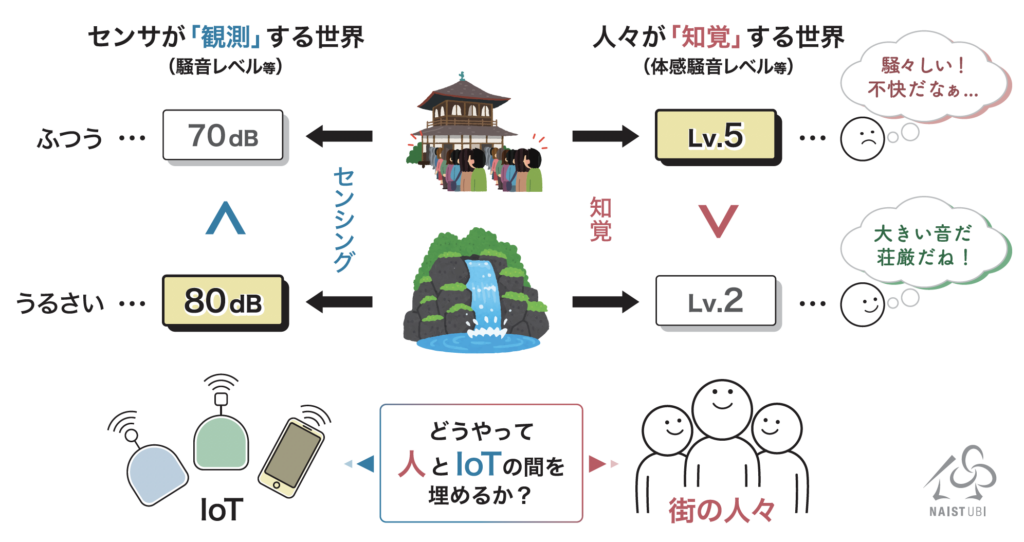
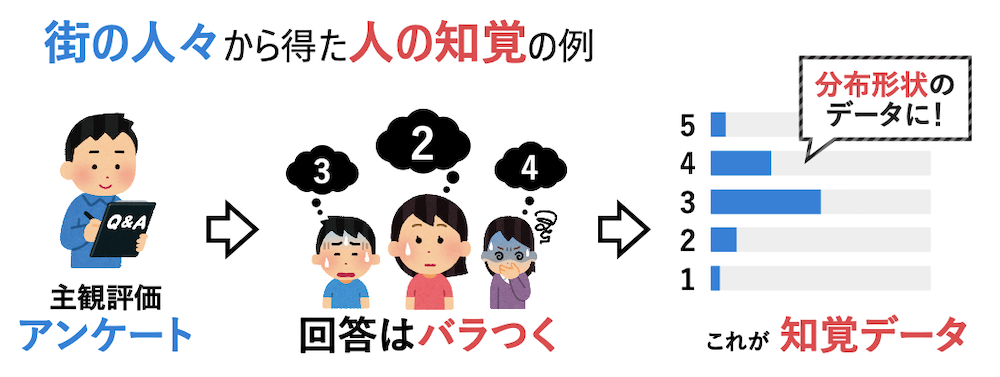
サイバネティクス・リアリティ工学研究室で助教をしております磯山直也です。サイバネティクス・リアリティ工学研究室では、バーチャルリアリティに関する研究を主軸としつつ、人とコンピューターが適切に・便利に・快適に・安全に・楽しく寄り添いつつ生活できることを目指して研究を行っています。詳しくはこちらをご覧ください。早速ですが、こちらの記事ではバーチャルリアリティではなく、ウェアラブルコンピューティングに関する研究の紹介を致します。
私はウェアラブルコンピューティングに関する研究を行っているのですが、その中でもウェアラブル機器に表示された映像が人に与える影響について着目しています。
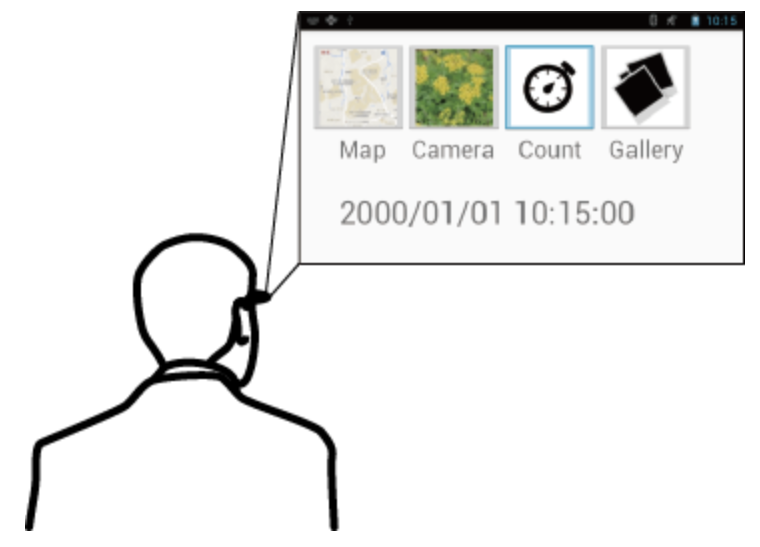
ウェアラブルコンピューティング環境では、コンピューターやセンサーなどを人が身につけた状態で生活することで、人がシステムから様々な恩恵を受けることができます。ウェアラブルコンピューティング環境で使用される機器の代表的なものにスマートグラスというものがあります。スマートグラスには様々な種類があるのですが、本記事では、ディスプレイが使用者の目の前に配置され、使用者はいつでも・どこでも視覚的な情報を見られるものを指すこととします。実際に販売されているスマートグラスとしては、Google社のGlass Enterprise Edition 2、Vuzix社のBlade、エプソン社のMOVERIO、ウエストユニティス社のInfoLinker3などがあります。記事を書いていたら、2021年8月にdocomoがGoogle社のGlass Enterprise Edition 2を発売するというニュースが飛び込んできたので楽しみですね。下図で装着しているのはVuzix社のM300です。

スマートグラスでできること
スマートグラスにはAndroid OSが搭載されているものが多く、スマートフォンの画面が目の前に置かれているような状態になります。スマートフォンのように機器を手に持たなくても、電車や歩行中でも視覚的な情報を見ることができます(もちろん、歩きスマホのような問題について考えることも大事です!!)。満員電車でも映画を見たりすることがスマートフォンよりも容易に可能です。手に機器を持たなくてもスマートグラスを操作できる仕組みも数多く研究されていますが、この記事では触れません(操作用の機器だけで長い記事になってしまいそうなので…)。
スマートグラスには加速度センサーやジャイロセンサー、GPSなどが搭載されているため、スマートグラス上のシステムは使用者が何をしているのか、どこ居るのかなどが認識できます。そのため、使用者の状態や位置に応じた情報を提示できます。例えば、「使用者が駅に近づいてきたら今の時刻と次の電車の出発時刻を提示」「使用者が休憩を始めたら先程まで見ていた動画の続きを自動で再生開始」「ランニングやサイクリング時に現在の速度を提示」「料理中に手順に合わせて自動でレシピを遷移」などが可能になります。
以上のように、スマートグラスは様々な使用方法があります。私の研究では、スマートグラスを使用する際には、スマートフォンを使用する際とは大きく環境が異なることに着目し、その特徴を活かした新しい使用方法や問題について扱っています。
常に情報を見るということ
さて、話は少し脱線しますが、人は見たもの・意識したものから行動や思考に影響を受けることが知られています。例えば、プライミング効果は、先行する刺激が後続の刺激に対する処理を促進もしくは抑制する効果として知られています。乗り物に関する会話をしていた後に「飛ぶものといえば?」と聞かれた際に、普段であれば鳥や雲と答えていたかもしれないのに、「飛行機」と答えやすくなるような現象です。単純接触効果は、特定のものに接する回数が増えるほど、それに対して好印象をもつようになる効果です。テレビCMなどでもこの効果が利用されています。アンカリング効果は、先に与えられた数字や条件が基準となって、後の情報に対する判断や行動に影響を与えられる効果です。店舗におけるポップで安売りを表示する際に元の価格を提示するのも、この効果が使用されています。ここまでに挙げた例以外にも人は様々な影響を受けています。
スマートグラスの話に戻りますと、スマートグラスの使用者は、何気なく・無意識に近い状態で画面を見ることがあります。その他の特徴として、何度も画面を見る・長時間同じ映像を見る・他の作業をしながら見る・何かをする直前に画面を見るなどが考えられます。上述したような効果はスマートグラス上に提示された視覚情報からも、使用者に対して与えられると考えられますが、これまでに調べられてきた効果よりも、強い効果が与えられる,あるいは,効果の弱まりが早い、などの異なる効果になる可能性があります。特定の映像を見ていると、元気が出てくる良い効果もあり得ますし、元気が無くなる悪い効果もあり得ます。そこで私は、スマートグラス上に提示される情報によって人はどのような影響を受けるのか、どのように活用できるのか、に関して研究を行っています。
以降では、これまでに研究した内容を二つ紹介したいと思います。
気になるものの変化
スマートグラス上には様々な情報を表示できます。しかし、使用者にとって見た方が良い情報ばっかり表示されていると、使用者が表示される情報を「全て見ないとっ!!」ってなってしまい、疲れちゃうなーと考えました。そこで使用者が特にスマートグラスを必要としていないときに、見なくても良いけど、見たら何かしら良い効果が得られる情報を表示できると良いな、と考えました。
人は、趣味に関連するような興味ある情報でも実世界上で多くの情報を見落としています。そこで、上述したプライミング効果をスマートグラスに表示した映像によって生起させることで、使用者が実世界上にある興味対象の情報を見落としにくくなるのではないかと考えました。

かなり小規模な実験だったのですが、スマートグラス上にサッカーの映像を表示した被験者は実世界上のサッカー関連の情報に、野球の映像を表示した被験者は野球関連の情報に気づきやすくなっていました。
より詳細にこの効果を調べるために、被験者が気になるものの変化について調査を行いました。被験者には、スマートグラスを使用して、散歩中に気になったものの写真を撮ってきてもらいます。この際に、被験者を3グループに分け、それぞれのグループに対して、カメラを起動するボタンのアイコンが「建物」「自然」「乗物」のいずれかの写真が表示されるようにしました。結果として、被験者は実験の目的を知らなかったのですが、「建物」の写真を見ていたグループは建物関連の写真を多く撮影して、「自然」の写真を見ていたグループは自然関連の写真を多く撮影していました。このように、スマートグラス上に表示した映像によって、使用者が気になるものに変化があることが確認できました。
作業速度の変化
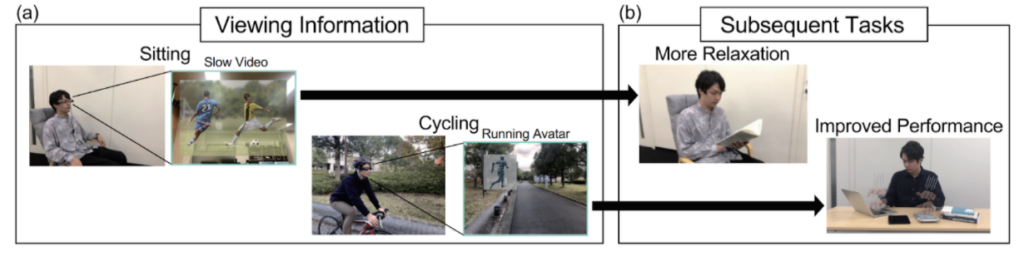
スマートグラスを利用することで、使用者は何か違う作業に入る直前まで特定の映像を見ていられます.そこで、職場へ行くまでの道中に見ていた映像によって、職場へ着いた際にスムーズに仕事を始められないか・仕事の速度が上げられないかと考えました。
実験では、スマートグラス上で再生する動画の速度を変化させたり、スマートグラス上に表示する人のアニメーションの走る速度を変化させたりしました。そして、見た後の被験者のタスクを行う速度に変化が無いか、を調査しました。実験の結果、通常より速い速度で再生されていると考えられる動画やアニメーションを見てからだとタスクを行う速度も上がり、遅い速度を見た後だとタスクを行う速度が遅くなることが確認できました。
今回の得られた結果では少し変化する程度でしたが、今後より強く影響の与えられる映像について探っていきたいと考えています。また、タスクが遅くなることにも着目し、休憩前に特定の映像を見ることでリラックスしやすくならないか、ということも調査していく予定です。
※ 本研究は2021年春に修了した長谷川くんが頑張ってくれました。長谷川くん、ありがとう。
今後の展望
今後、スマートグラスは一般に普及すると信じているのですが、その際には広告媒体として大きく注目されることが想像できます。特定の商品だけが購入されやすくなることを避けるように、使用ガイドラインを作成する必要があります。そのガイドラインのためにも多くの影響について明らかにしておくことが重要であると考えています。しかし、そのような禁止事項を増やすだけでは苦しくて、楽しくも無いので、便利な使い方に関してもどんどんと提案していきたいと考えています。まだ研究できていないので、具体的な案をここでは書きづらいですが、「初対面の人に会う前に、その人の顔を事前に表示し続けておくことで、いざ会ったときにリラックスして話せるようになる」「その日に食べた昼食を表示し続けることによって食べたことが記憶に残りやすくなり、お腹が減りにくくなる」などの利用ができたら良いなと考えています。
著者紹介
磯山 直也(いそやま なおや)
2015年に神戸大学で博士(工学)を取得後、同年に青山学院大学の助教に着任。2017年に神戸大学の特命助教に着任した後、2019年から奈良先端科学技術大学院大学にて助教として勤務。ウェアラブルコンピューティング・ユビキタスコンピューティング・エンタテインメントコンピューティング・バーチャルリアリティの研究に従事。
🔗 Webサイト: http://dr-iso.com