ユビキタスコンピューティングシステム研究室(以下 ユビ研)助教の松田裕貴です。ユビ研では、人々の生活に溶け込んだ様々なコンピュータを活用することで、人や人を取り巻く環境を観測し、状況を理解し、人や環境に還元することで、人々の生活をよりスマートにすることをミッションとして研究に取り組んでいます。使用するコンピュータは多種多様で、スマートフォンやスマートウォッチといった人が身につけるモノや、スマートスピーカーやスマート家電といったモノなど、近年で「IoT(Internet of Things)」と呼ばれる機器すべてが対象となります。
今回は、科学技術振興機構の令和2年度戦略的創造研究推進事業(JSTさきがけ)に採択されたプロジェクト(採択課題名: 人の知覚を用いた参加型IoTセンサ調整基盤の創出、以下 さきがけ研究)について、これまで取り組んできた研究の説明を交えつつ紹介します。プロジェクトの肝である「人の知覚」や「IoTセンサ調整」といったキーワードが一体何なのか?ということを解説できればと思います。
# JSTさきがけとは
出典: さきがけ プログラムの概要
国の科学技術政策や社会的・経済的ニーズを踏まえ、国が定めた戦略目標の達成に向けた独創的・挑戦的かつ国際的に高水準の発展が見込まれる先駆的な目的基礎研究を推進します。科学技術イノベーションの源泉となる成果を世界に先駆けて創出することを目的とするネットワーク型研究(個人型)です。
# 採択課題の概要
出典: さきがけ「IoTが拓く未来」領域 令和2年度採択課題
IoTが都市の至る所に設置される未来のスマートシティでは、データに基づく様々なサービスが日常生活をより豊かにするでしょう。その実現には、センサデータを統合し私達の「感覚」に寄り添った情報を取り出すための持続可能な基盤が必要となります。本研究では都市IoTセンサを「人々の知覚」によって調整することで、種類・精度の異なるセンサデータを統合する「ユーザ参加型IoTセンサ調整基盤」の創出を目指します。
参加型センシングによる夜道の安全性判定
まず初めに、さきがけ研究の着想の原点となる研究を紹介します。
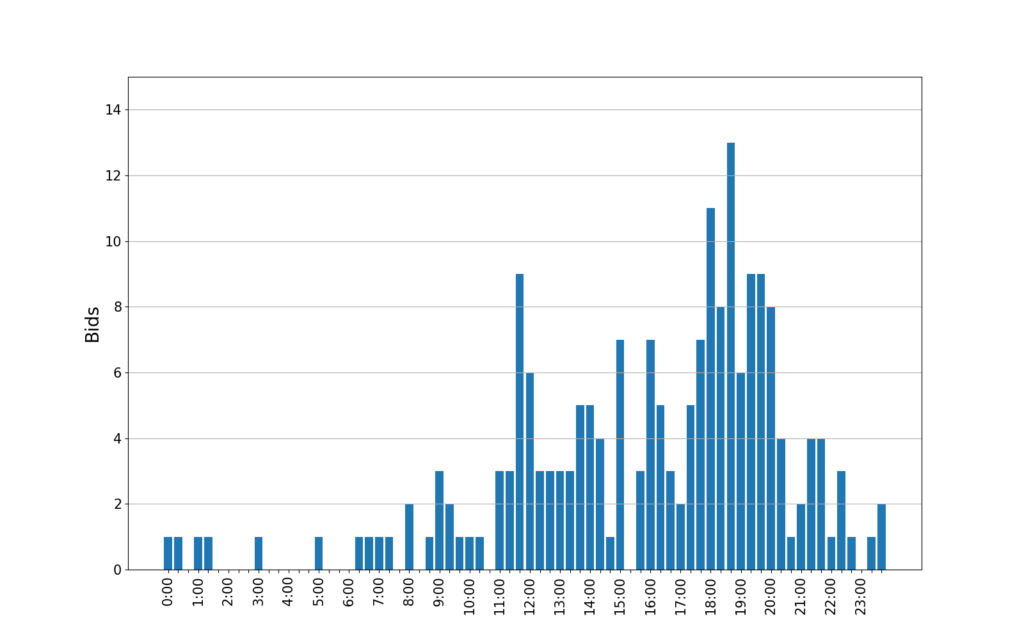
この研究では、夜道の安心・安全な経路を案内できるナビゲーションを実現するために、夜道がどの程度明るく安全であるかをセンシングによって明らかにすることを目的としています。しかし、街中の情報を網羅的に集めることはなかなか容易ではありません。そこで、一般市民が普段から使用しているスマートフォンのセンサでデータを収集・提供してもらうことで、集合知的に都市環境の把握を目指す「参加型センシング」という技術を活用します。具体的には下図のような手順で、街灯が設置されている位置やその明るさのデータを収集・分析し、夜道の安全性を判定します。
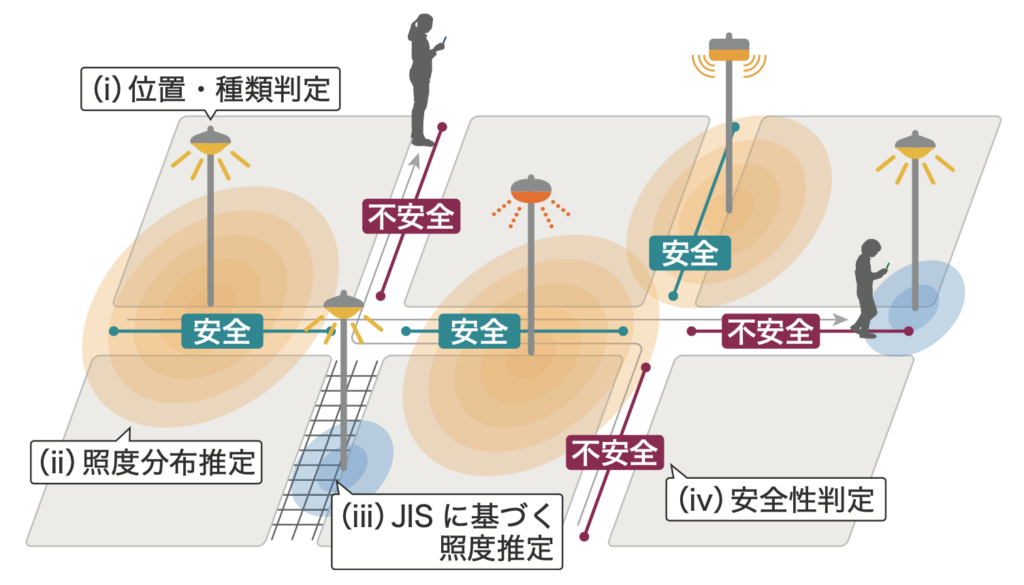
データ収集の結果は以下のようになります。なんとなくどの道が明るそうといったことが読み取れそうですね。このデータを元にして、道路に設置された光源(街灯など)がどこにあってどの程度の明るさであるかを推定し、それぞれの道の安全性を判定していきます(判定には日本防犯設備協会の定める基準を使用)。
一見、この研究が達成されれば、人々に安心・安全な夜道を案内するガイダンスシステムが作れそうに思えますが、人が実際に「安心」と感じるかどうかという主観的な部分がカバーできていません。
人のセンシングによる観光客の心理状態推定
つぎに、対象とする状況・内容は上記と異なりますが、人の主観的な情報(人がどう感じるのか?)を明らかにする研究として、観光中の観光客の心理状態推定に関する研究を紹介します。
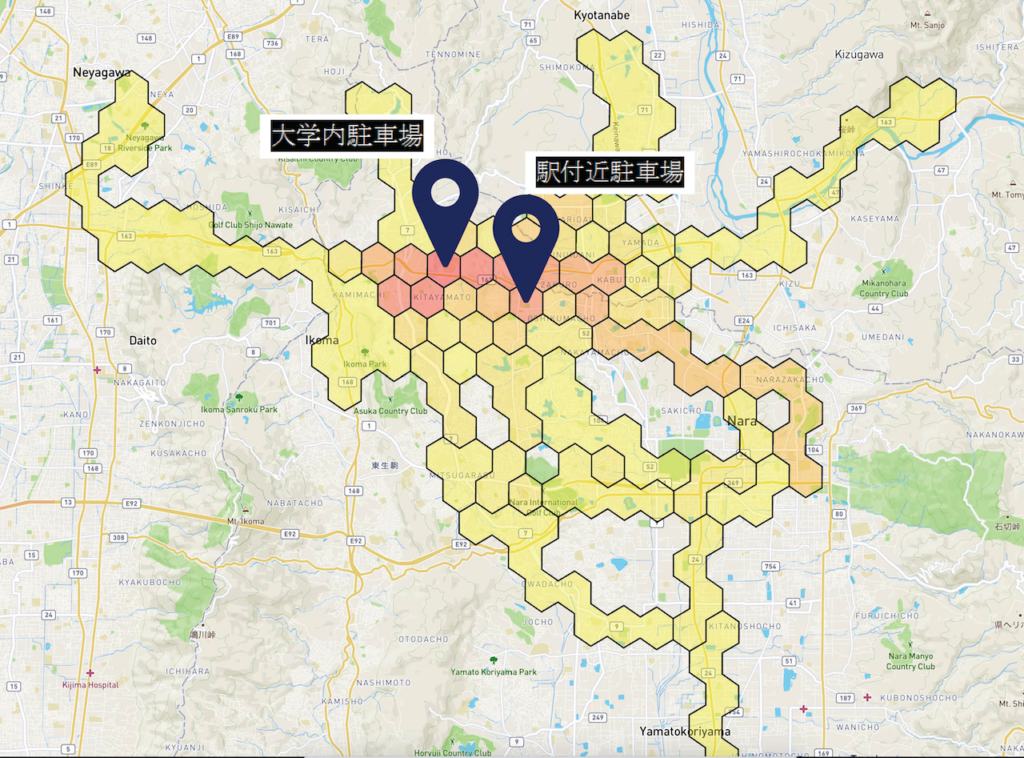
この研究では、観光客が観光スポットを訪れた際にどの程度満足したのか?どういった感情を抱いたのか?という情報を元に、次に推薦するスポットを動的に調整する新しい観光ガイダンスを実現することを目的としています。しかし、観光していく中で毎回アンケートに回答するのは面倒ですよね。そこで、観光客の無意識にとる仕草や生体反応をもとに、観光客の心理状態を推定できるようにしようというのがこの研究です。下図のように、観光中の観光客の持つデバイスから情報を収集・分析することで感情や満足度を推定するモデルを構築しています。
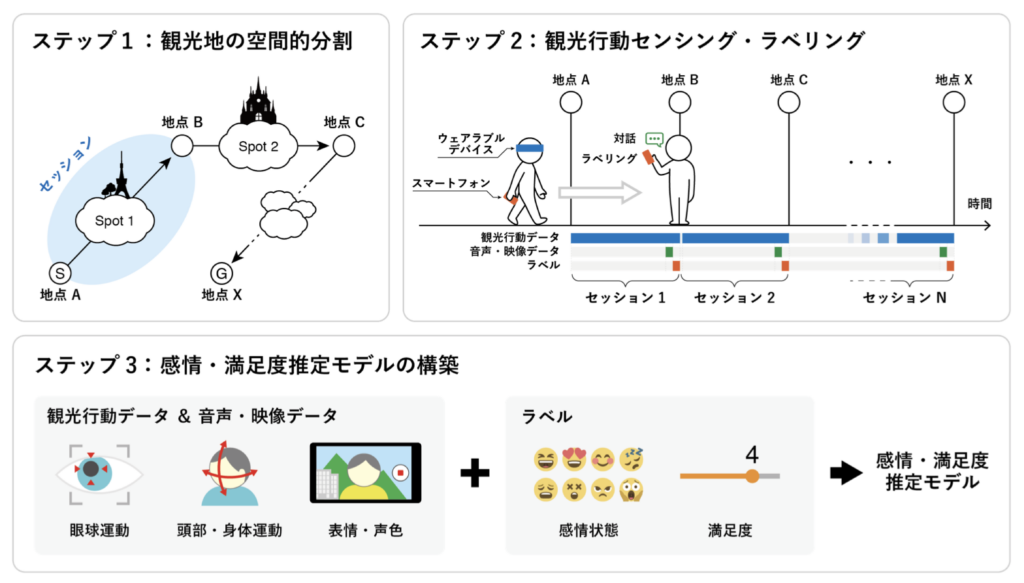
実際に様々なセンサを装着してもらいつつ観光実験をしている様子が以下です。これによって得られたデータをつかって、心理状態推定モデルを構築します。まだまだ精度は高いとは言えませんが、7段階評価の満足度推定に関しては1段階程度の誤差で推定できるようになっています。

この研究を進めていくうちに、人の心理状態は環境にも大きく影響を受けている可能性が示唆されており、やはり「環境を対象としたセンシング」と「人がどう感じるか?」ということを繋いであげる新たな研究が必要であろうという視点が生まれてきました。
さきがけ研究で目指すこと
こうした背景から、さきがけ研究がスタートしました。
さきがけ研究では、参加型センシングの仕組みを用いて「人がどう環境を認識・解釈しているのか?(=知覚)」という情報を街中で収集し、都市環境に存在するIoTセンサから得られるデータとの関連性を見出すことによって、人がどう感じるか?を理解できる次世代のIoT(IoPT: Internet of “Perception-aware” Things)を創り出すための基盤の実現を目指しています。
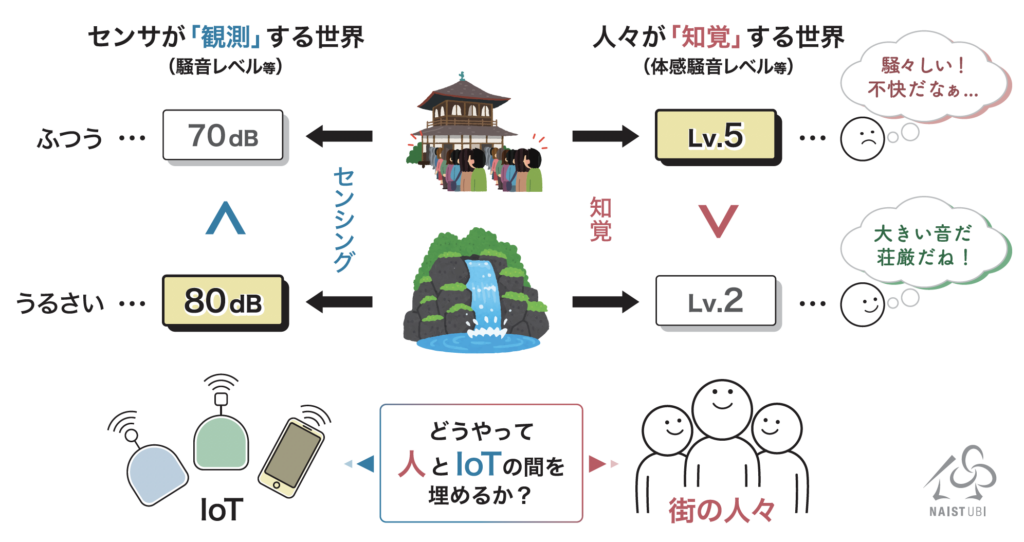
一般にセンサの較正というと、より正確な測定器を使ってセンサの出力値を調整するのが一般的ですが、さきがけ研究では、人がどう感じるか?という主観的なデータ(知覚データと呼びます)を「正解データ」としてセンサの出力値を調整することに違いがあります。知覚データの収集は人間にしかできませんが、特別なセンサを必要とせず各々の感覚を正解として取り扱うことができるため、スマートフォンを用いた参加型センシングを応用することで、時空間的に網羅的なデータ収集が期待できます。
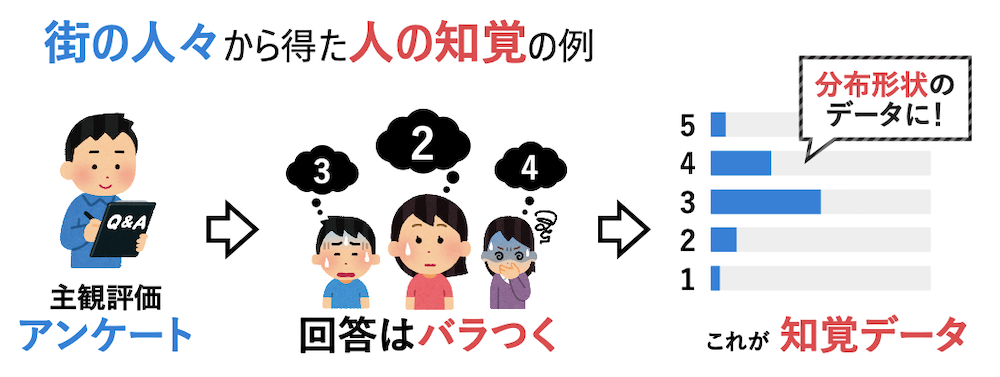
しかしながら、一般的な較正と異なり、人の知覚は個人差が存在するため、正解データは一意に定まりません。例えば、知覚データを5段階評価で集めるとすると、全ての人が「3」と答えるわけではなく「2」や「4」なども回答に含まれる(分布形状となる)ことが考えられます。そのような曖昧な「知覚」をどのように表現するのか、どのようにセンサを調整するのか、というところが研究のポイントとなります。
この研究を通じて、「機械」と「人」とのギャップを埋め、より人の知覚に寄り添ったスマートシティを実現することを目指します。
現在は、自治体や民間企業との連携体制を構築しているところで、これから実際の「街」でこの研究に関する実証実験を進めていく予定です。
著者紹介
松田裕貴(まつだ ゆうき)
明石工業高等専門学校専攻科を卒業後、奈良先端科学技術大学院大学(NAIST)にて博士前期・後期課程を修了。博士(工学)。情報科学技術と人間との協調によるヒューマン・イン・ザ・ループなシステムを中心に、IoTやAIを活用したより高度な社会を実現するための研究に取り組んでいる。研究成果を応用し開発した「夜道を安心して帰宅できるよう支援するナビゲーションシステム」は、オープンデータアプリ総務大臣奨励賞を獲得するなど高く評価された。最近では、都市環境におけるユーザ参加型センシングとスマートデバイスを用いた心理状態推定を研究テーマとして取り上げ、実環境ベースでの研究を進めている。
🔗 Webサイト: https://yukimat.jp/