ソフトウェア設計学研究室 助教の平尾俊貴です。本研究室では、ソフトウェアやソフトウェアを含むシステムの開発・設計を支援する技術についての研究を実施しています。特に、ソフトウェアに関するデータ(ソースコードや開発履歴など)の分析、開発プロセスや設計情報の解析、SDN(ソフトウェアディファインドネットワーク)を中心とした仮想化システム基盤構築技術、ソフトウェアアナリティクス(より適切な意思決定のためにソフトウェア開発の現状把握の深掘りを助けるためのデータ分析)、HPC(ハイパフォーマンスコンピューティング、スーパコンピュータを用いた大規模な科学技術計算)などです。詳しく知りたい方は、本研究室HP(https://sdlab.naist.jp/)をご覧ください。
今回は、ソフトウェア設計学の技術や考え方を応用して社会実装しているプロダクトである『C2Room』と、私の学生である福本君が研究している『コーディングルールを理解したコード補完システム』を御紹介します。
生徒の手もとが見える、遠隔授業システムC2Room
新型コロナウイルスの感染拡大に伴い、遠隔教育の需要は急速に増加しました。EdTech(エドテック:教育×テクノロジー)業界の市場規模は、2023年までに約3,000億円まで成長する見込みです。あらゆる教育機関(学校、学習塾、企業研修など)では、一般的なビデオ会議ツール(Zoomなど)を活用して、遠隔地からライブ配信の授業を実施してきました。遠隔教育は感染対策だけでなく、場所を問わず平等な教育を受けられるため、世界的に需要が加速しています。
遠隔授業が抱える共通の課題として、生徒の状況(手もとの動き、理解度など)を遠隔で把握することが難しく、十分な指導が行き届かないことが挙げられます。躓いている生徒を早期に支援することが難しく、結果的に各生徒間で学習格差が生じます。これが教育業界全体での喫緊の課題になっています。
この課題を解決できるプロダクトとして、遠隔授業システム「C2Room」を奈良先端大で開発しました。本システムは、いつでもどこからでも生徒の手もとが見える授業支援システムです。例えば生徒100人のノートが一画面でリアルタイムに見ることができます。生徒と指導者の画面があり、各生徒はタッチペンで問題を解きます。そして、指導者はクラス全員の生徒の解答内容をリアルタイムで画面上から見ることができ、遠隔授業でも生徒の手もとを把握することができ、より細かな遠隔指導を実現することが可能になります。

このプロダクト自体は、教育業界で現場指導者らが抱えるリアルなニーズに着目してるため、大々的にソフトウェア設計技術を披露しているものではありません。しかしながら、ソフトウェア設計学で重要視しているデザインセンスという概念は常に開発工程で取り入れており、時代と共に変化する開発技術を広く適応できる柔軟な設計にしております。また、生徒の学習過程で発生するデータを解析して、生徒の進捗をより効率よく管理できる技術なども派生的に生み出しており、実証的な研究へと発展しています。
コーディングルールを理解した、コード補完システム
コード補完とは、皆さんのスマートフォンにもあるIMEの入力補完と似た機能で、よりプログラミングに特化した機能です。コード補完はプログラマのタイプミスを防いだり開発速度を向上させる効果があり、実際にプログラマがプログラミング中に最も高い頻度で使う機能です。
従来のコード補完は開発プロジェクトに存在するソースコードを解析して、ソースコードに登場する単語やクラスの構造をIDEが把握し、その情報に基づいて入力中の文字からプログラマが入力したい単語を推定する機能が一般的でした。一方で、近年の機械学習(AI)の発達に伴って従来のコード補完より賢い、プログラマとAIが共創してプログラムを完成させるようなコード補完を目指して、機械学習を活用したコード補完が研究されています。
我々はコード補完の精度をより高めるために、プロジェクトに合わせたコード補完の手法を模索しています。OSSでは複数人のプログラマが共同でプログラムを書くため、無秩序なソースコードを書かないようにするためのルール(コーディング規約、アーキテクチャ)が存在します。例えばプログラムに登場する変数やクラスなどの名前の付け方やどういった構造でクラスを設計するかが決められています。また、いくつかの定数や関数はプロジェクトのあらゆるソースコードから繰り返し使われるものも存在します。このようにプロジェクトごとにソースコードに固有の特徴があります。一方で従来手法は、様々なプロジェクトから集められた大量のソースコードを用いて学習されているため、実際のプロジェクトで使用する際に、そのプロジェクトの特徴を考慮して補完することができません。
そこで我々は、ドメイン適応という手法を使ってプロジェクトに特化したコード補完ができるモデルを作成します。ドメイン適応とは最終的に学習させたいデータを学習させる前に、より広汎なドメインから作成した大規模なデータセットを使って学習させる手法です。この2段階の学習によってモデルがある程度の汎用的な知識を持った状態で対象ドメインのデータの学習をするので、特にデータセットが少なくても学習させることができます。
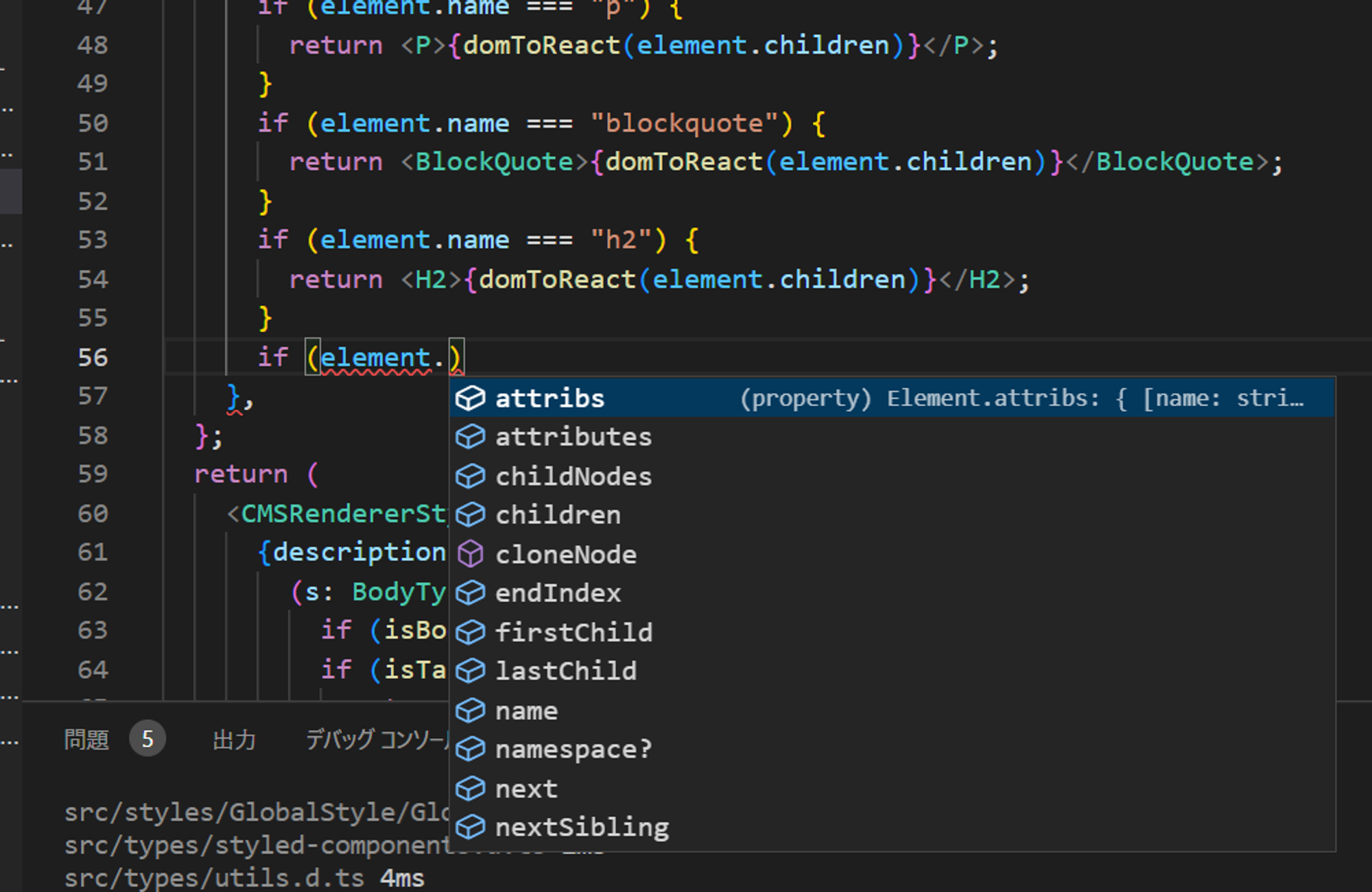
例えば以下の図において、実プロジェクトであるSpring Frameworkのコードの2行目Assertに続くの部分(つまり<X>)を補完するとします。従来手法や我々の手法を用いた場合、共通してNull値をチェックする関数を補完することができました。ただし、従来手法では「isNotNull」という関数を、我々の手法では「notNull」という関数を補完しました。一見どちらも正しい様に見えますが、Spring Frameworkではコーディング規約で「notNull」という関数を使ってヌルチェックをするというルールがあるため、我々の手法の方がよりプロジェクトに合わせた補完を行っていました。このように、開発者が参加するプロジェクトのルールに則したコード補完を実現することで、ソフトウェア開発効率の向上に貢献しています。

著者紹介
平尾俊貴(ひらお としき)
奈良先端科学技術大学院大学 博士(工学)。日本学術振興会 特別研究員DC1 採用。ソフトウェア品質管理プロセスの自動化に関する研究に従事。機械学習、ビッグデータ分析、プログラム解析、及び自然言語処理が研究領域。世界大学ランキング上位のMcGill大学(カナダ)で訪問研究員として、機械学習とビッグデータ分析技術を活用したソフトウェア開発支援システムを共同開発。 その後、アメリカに渡り、世界4大産業用ロボットメーカー ABB Group(2020年度 従業員数:10万5千人、売上規模:2.9兆円)にてソフトウェア研究者として、数多くの産学連携プロジェクトを牽引。 ABB社の双腕型ロボットYuMiを活用して工場生産ラインの自動化に向けた研究などが顕著。 ソフトウェア業界で世界的に権威のある国際会議ICSEやFSE、海外論文誌TSEなどで研究成果を数多く発表した実績。特任助教及び(株)dTosh 代表取締役として、現在は数多くの グローバルな産学連携事業を牽引。Virginia Commonwealth University (アメリカ)、University of Waterloo (カナダ)などと連携し、数多くの企業をデジタル変革する研究支援を実施。
福本 大介(ふくもと だいすけ)

奈良県桜井市出身。奈良工業高等専門学校を卒業後、奈良先端科学技術大学院に入学し、ソフトウェア設計学研究室に配属。現在、博士前期課程2年。2021年度のGeiotを受講し、複数のビジコンやハッカソンで入賞(JPHACKS2021 / Best Hack Award・Best Audience Award・スポンサー賞、立命館大学学生ベンチャーコンテスト2021 / 優秀賞・スポンサー賞)。プログラミングの支援に興味があり、深層学習を用いたコード補完の研究に従事。